第 13 章 集成学习与梯度提升决策树
本章将会首先介绍集成学习的思路以及一些常用的集成学习方法,然后介绍梯度提升决策树模型。在前面的章节中,我们讲解了许多不同的机器学习算法,每个算法都有其独特的优缺点。同时,对于同一个任务,往往有多种算法可以将其解决。例如我们要将平面上的一些点分类,假设算法一和算法二的正确率是75%,算法三是50%。3种算法都已经通过调参达到了其最优表现,已经无法再进一步了。那么,我们是否能通过组合这些算法,得到比75%更高的正确率呢?看上去组合之后,算法三会拖算法一和二的后腿,反而会拉低整体表现,更别说提升了。然而,我们考虑表13-1中的例子。
表 13-1 通过较差算法组合出更好的算法
| 样本 | 算法一 | 算法二 | 算法三 | 多数投票 |
|---|---|---|---|---|
| A | √ | √ | × | √ |
| B | × | √ | √ | √ |
| C | √ | × | √ | √ |
| D | √ | √ | × | √ |
该例中共有4个样本,各个算法的正确率也符合我们的假设。对每个样本,我们用多数投票制(majority voting)集成3个算法的输出,也即是3个算法分别给出预测的分类,再取较多者作为最终预测。令人惊讶的是,虽然3个算法单独最高的正确率仅有75%,它们组合之后竟然达到了100%的正确率。仔细观察可以发现,算法一预测错误的B样本,算法二和三都预测正确了。其他样本也类似,当一个算法在此有缺陷时,另外两个算法就可以将其弥补。这一现象启发我们,我们可以通过将不同算法得到的模型按某些方式进行组合,取长补短,从而获得比任一单个模型都要好的表现,这就是集成学习(ensemble learning)的思想。上面的例子中,我们采用了最简单的投票组合方法。接下来,我们来介绍几种实践中常用的集成学习方法。
13.1 自举聚合与随机森林
在机器学习模型的基本思想一章中,我们曾讲解过交叉验证方法。该方法将数据集随机划分成
顾名思义,bagging算法由自举和聚合两部分构成。其中,自举指的是自举采样(bootstrap sampling)。与交叉验证中的无重复均匀划分不同,自举采样为了保证随机性,尽可能降低不同子数据集之间的相关性,采用了允许重复的有放回采样。假设数据集的大小为
也就是说,每次按自举采样法采出的大小与原数据集大小相同的样本集合,平均都包含了
假设我们共进行了
在交叉验证中,我们的目标是通过多个模型选出最优的超参数,因此我们为每个模型单独计算损失后再取平均。而在bagging算法中,我们希望将这些模型聚合成表现更好的新模型,因此应当衡量最后集成模型的整体效果。我们既可以像普通的机器学习算法那样,提前将数据集中第一部分划分出来作为测试集,不参与聚合采样;也可以计算bagging算法的out-of-bag(OOB)误差。对于数据集中的每个样本
为了分析bagging算法的作用原理,我们来考虑bagging相比于单个模型的提升部分。首先对机器学习的预测误差做一个普适性的偏差-方差分解(bias-variance decomposition)分析。设数据的分布为
其中,
由于bagging中得到每个模型的过程都是独立且相同的,其期望误差和方差可以认为相同,我们将其分别记为
假设不同模型之间的相关系数为
考虑到不同模型所用的数据集是按相同方式采样的,其相关系数应满足
对于决策树模型,其bagging算法的改进版本又称为随机森林(random forest),如图13-1所示。除了用bagging方法为每个决策树随机采样进行训练之外,上面的推导说明,bagging在不同数据集上训练出的模型相关性较强的时候,降低方差的能力会被削弱。因此,为了进一步降低模型的相关性关系,在决策树每次分裂节点前,我们都从全部的
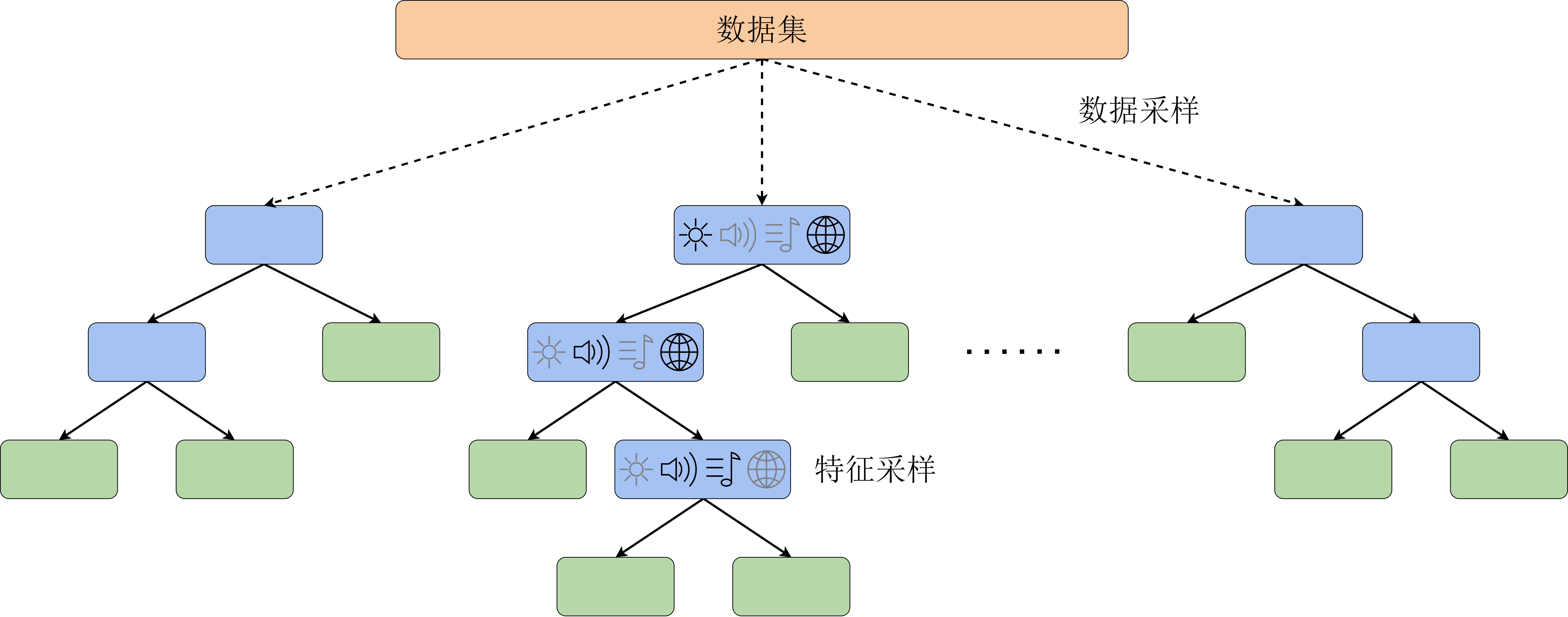
下面,我们来动手实现决策树的bagging算法和随机森林算法,并测试其在分类任务上的表现。简单起见,决策树的部分我们直接采用sklearn中的 DecisionTreeClassifier。为了体现出随机森林采样特征的特点,我们用sklearn中的工具生成一个高维的点集用作分类数据集。
from tqdm import tqdmimport numpy as npfrom matplotlib import pyplot as pltfrom sklearn.datasets import make_classificationfrom sklearn.tree import DecisionTreeClassifier as DTCfrom sklearn.model_selection import train_test_split# 创建随机数据集X, y = make_classification(n_samples=1000, # 数据集大小n_features=16, # 特征数,即数据维度n_informative=5, # 有效特征个数n_redundant=2, # 冗余特征个数,为有效特征的随机线性组合n_classes=2, # 类别数flip_y=0.1, # 类别随机的样本个数,该值越大,分类越困难random_state=0 # 随机种子)print(X.shape)
(1000, 16)
接下来,我们实现bagging和随机森林的部分。由于这两个算法只有决策树分裂节点时不同,而数据采样部分相同,我们将其写成一个类,用参数来控制执行哪个算法。
class RandomForest():def __init__(self, n_trees=10, max_features='sqrt'):# max_features是DTC的参数,表示节点分裂时随机采样的特征个数# sqrt代表取全部特征的平方根,None代表取全部特征,log2代表取全部特征的对数self.n_trees = n_treesself.oob_score = 0self.trees = [DTC(max_features=max_features)for _ in range(n_trees)]# 用X和y训练模型def fit(self, X, y):n_samples, n_features = X.shapeself.n_classes = np.unique(y).shape[0]# 集成模型的预测,累加单个模型预测的分类概率,再取较大值作为最终分类ensemble = np.zeros((n_samples, self.n_classes))for tree in self.trees:# 自举采样,该采样允许重复idx = np.random.randint(0, n_samples, n_samples)# 没有被采到的样本unsampled_mask = np.bincount(idx, minlength=n_samples) == 0unsampled_idx = np.arange(n_samples)[unsampled_mask]# 训练当前决策树tree.fit(X[idx], y[idx])# 累加决策树对OOB样本的预测ensemble[unsampled_idx] += tree.predict_proba(X[unsampled_idx])# 计算OOB分数,由于是分类任务,我们用正确率来衡量self.oob_score = np.mean(y == np.argmax(ensemble, axis=1))# 预测类别def predict(self, X):proba = self.predict_proba(X)return np.argmax(proba, axis=1)def predict_proba(self, X):# 取所有决策树预测概率的平均ensemble = np.mean([tree.predict_proba(X)for tree in self.trees], axis=0)return ensemble# 计算正确率def score(self, X, y):return np.mean(y == self.predict(X))
我们通过调整max_feature参数的值来测试两种算法的表现,其中None代表bagging算法,sqrt代表随机森林算法。最后,我们再将两种算法的训练准确率和OOB分数随其中包含的决策树个数的变化曲线画在一张图中,方便对比两种算法的表现。
# 算法测试与可视化num_trees = np.arange(1, 101, 5)np.random.seed(0)plt.figure()# bagging算法oob_score = []train_score = []with tqdm(num_trees) as pbar:for n_tree in pbar:rf = RandomForest(n_trees=n_tree, max_features=None)rf.fit(X, y)train_score.append(rf.score(X, y))oob_score.append(rf.oob_score)pbar.set_postfix({'n_tree': n_tree,'train_score': train_score[-1],'oob_score': oob_score[-1]})plt.plot(num_trees, train_score, color='blue',label='bagging_train_score')plt.plot(num_trees, oob_score, color='blue', linestyle='--',label='bagging_oob_score')# 随机森林算法oob_score = []train_score = []with tqdm(num_trees) as pbar:for n_tree in pbar:rf = RandomForest(n_trees=n_tree, max_features='sqrt')rf.fit(X, y)train_score.append(rf.score(X, y))oob_score.append(rf.oob_score)pbar.set_postfix({'n_tree': n_tree,'train_score': train_score[-1],'oob_score': oob_score[-1]})plt.plot(num_trees, train_score, color='red',label='random_forest_train_score')plt.plot(num_trees, oob_score, color='red', linestyle='--',label='random_forest_oob_score')plt.ylabel('Score')plt.xlabel('Number of trees')plt.legend()plt.show()
100%|███████████████████████████████████████| 20/20 [00:14<00:00, 1.40it/s, n_tree=96, train_score=1, oob_score=0.888]100%|███████████████████████████████████████| 20/20 [00:04<00:00, 4.34it/s, n_tree=96, train_score=1, oob_score=0.897]
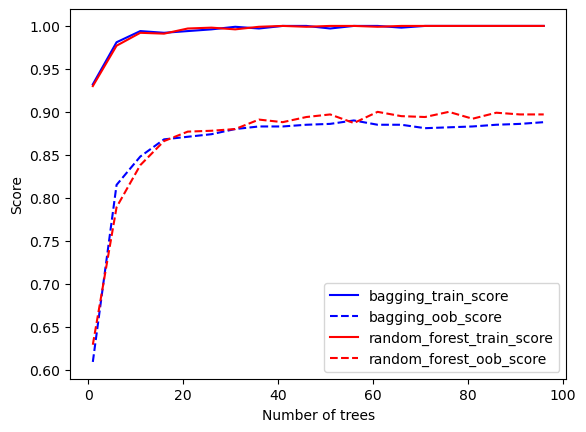
从上面的训练结果可以看出,当数据集比较小的时候,随机森林算法相比于简单的bagging算法,可以更有效地防止过拟合。此外,由于随机森林对特征进行了采样,在选择最优特征进行划分时需要的时间也更少,当包含的决策树数量较多时,其训练时间显著小于bagging算法。读者可以通过调整最开始生成数据集的参数观察两种算法效果的变化,当数据集中的样本个数或者数据维度越来越多时,过拟合现象会被自然削弱,随机森林的优势也随之下降。当然,bagging算法只是一个集成学习的框架,除了决策树之外,还可以应用到神经网络等其他不同的模型上。
最后,我们用sklearn中的bagging和随机森林算法在同样的数据集上进行测试,与我们上面的结果进行比较,验证实现的正确性。
from sklearn.ensemble import BaggingClassifier, RandomForestClassifierbc = BaggingClassifier(n_estimators=100, oob_score=True, random_state=0)bc.fit(X, y)print('bagging:', bc.oob_score_)rfc = RandomForestClassifier(n_estimators=100, max_features='sqrt',oob_score=True, random_state=0)rfc.fit(X, y)print('随机森林:', rfc.oob_score_)
bagging: 0.885随机森林: 0.897
13.2 集成学习器
Bagging算法虽然适用范围较广,但其底层的基础模型需要是同一种类的,例如都是决策树或都是神经网络。否则,其理论推导中假设的各个模型的平均偏差和方差相同的假设将不再成立,其提升模型稳定性的效果也难以保证。假设我们训练好了
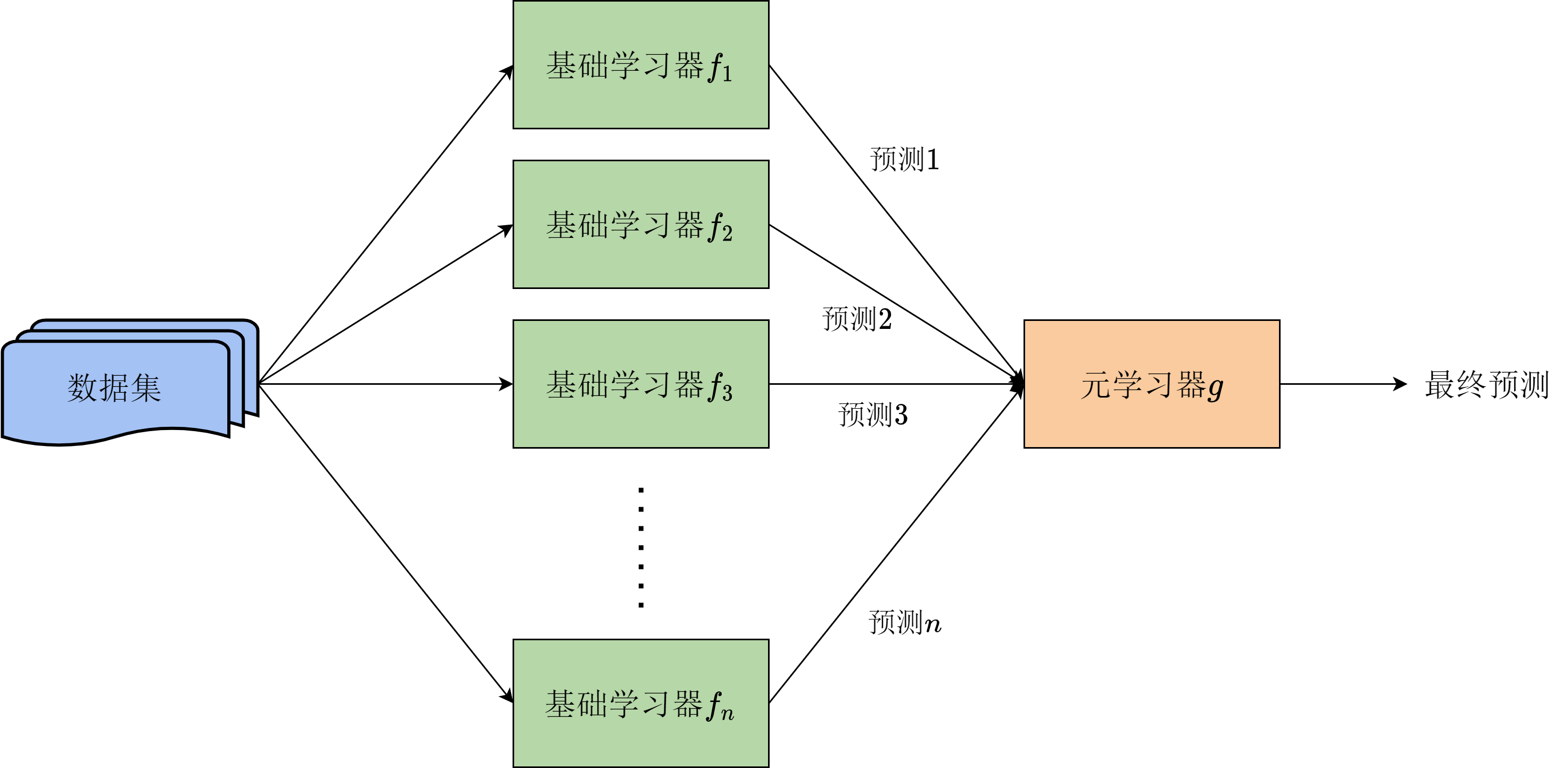
事实上,该思路在本章最开始的例子中已经有所体现,其中使用的元学习器的作用是选择
在由基础学习器构建元学习器的训练数据集时,如果让基础学习器直接在原本的训练集上进行预测,那么有极大可能发生过拟合现象,得到的数据质量不高。如果让其在划分出的验证集上预测,那么训练集的部分就无法用来训练元学习器,造成数据浪费。为了尽可能提升数据利用效率,同时保证数据质量,我们通常采用堆垛(stacking)方法,如图13-3所示。假设目前训练的模型是
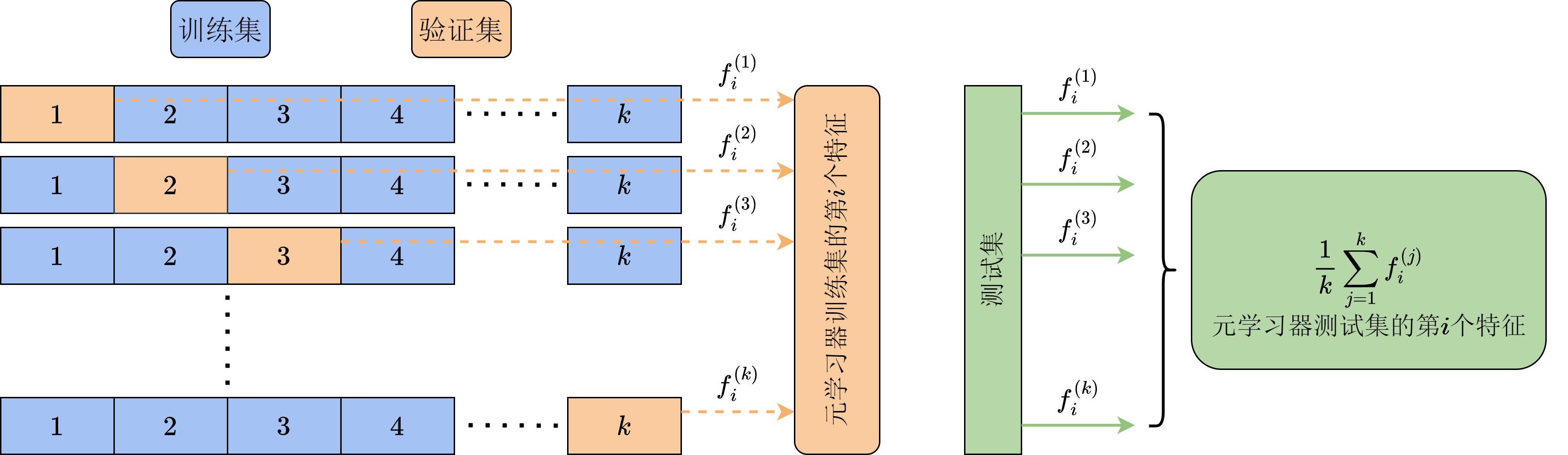
对每个基础学习器重复这一步骤,我们就得到了完整数据集上的
此外,有时我们会将原本的数据
下面,我们来动手实现堆垛方法。简单起见,我们直接使用sklearn库中的一些模型作为基础学习器和元学习器。
from sklearn.model_selection import KFoldfrom sklearn.base import clone# 堆垛分类器,继承sklearn中的集成分类器基类EnsembleClassifierclass StackingClassifier():def __init__(self,classifiers, # 基础分类器meta_classifier, # 元分类器concat_feature=False, # 是否将原始数据拼接在新数据上kfold=5 # K折交叉验证):self.classifiers = classifiersself.meta_classifier = meta_classifierself.concat_feature = concat_featureself.kf = KFold(n_splits=kfold)# 为了在测试时计算平均,我们需要保留每个分类器self.k_fold_classifiers = []def fit(self, X, y):# 用X和y训练基础分类器和元分类器n_samples, n_features = X.shapeself.n_classes = np.unique(y).shape[0]if self.concat_feature:features = Xelse:features = np.zeros((n_samples, 0))for classifier in self.classifiers:self.k_fold_classifiers.append([])# 训练每个基础分类器predict_proba = np.zeros((n_samples, self.n_classes))for train_idx, test_idx in self.kf.split(X):# 交叉验证clf = clone(classifier)clf.fit(X[train_idx], y[train_idx])predict_proba[test_idx] = clf.predict_proba(X[test_idx])self.k_fold_classifiers[-1].append(clf)features = np.concatenate([features, predict_proba], axis=-1)# 训练元分类器self.meta_classifier.fit(features, y)def _get_features(self, X):# 计算输入X的特征if self.concat_feature:features = Xelse:features = np.zeros((X.shape[0], 0))for k_classifiers in self.k_fold_classifiers:k_feat = np.mean([clf.predict_proba(X)for clf in k_classifiers], axis=0)features = np.concatenate([features, k_feat], axis=-1)return featuresdef predict(self, X):return self.meta_classifier.predict(self._get_features(X))def score(self, X, y):return self.meta_classifier.score(self._get_features(X), y)
我们选择KNN、随机森林和逻辑斯谛回归作为基础分类器,用逻辑斯谛回归作为元分类器。下面展示了单个基础分类器与最后的元分类器在数据集上的效果,可以看出,将不同分类器组合后得到的集成分类器要由于任何一个单个分类器。同时,将原始数据拼接到新数据上会使数据中的干扰信息增加,降低集成分类器的效果。读者可以进一步尝试非线性的元分类器,如神经网络和决策树,再次观察原始数据拼接到新数据上的模型预测性能的改变,这一任务留作习题。
from sklearn.linear_model import LogisticRegression as LRfrom sklearn.ensemble import RandomForestClassifier as RFCfrom sklearn.neighbors import KNeighborsClassifier as KNC# 划分训练集和测试集X_train, X_test, y_train, y_test = \train_test_split(X, y, test_size=0.2, random_state=0)# 基础分类器rf = RFC(n_estimators=10, max_features='sqrt',random_state=0).fit(X_train, y_train)knc = KNC().fit(X_train, y_train)# multi_class='ovr'表示二分类问题lr = LR(solver='liblinear', multi_class='ovr',random_state=0).fit(X_train, y_train)print('随机森林:', rf.score(X_test, y_test))print('KNN:', knc.score(X_test, y_test))print('逻辑斯谛回归:', lr.score(X_test, y_test))# 元分类器meta_lr = LR(solver='liblinear', multi_class='ovr', random_state=0)sc = StackingClassifier([rf, knc, lr], meta_lr, concat_feature=False)sc.fit(X_train, y_train)print('Stacking分类器:', sc.score(X_test, y_test))# 带原始特征的stacking分类器sc_concat = StackingClassifier([rf, knc, lr], meta_lr, concat_feature=True)sc_concat.fit(X_train, y_train)print('带原始特征的Stacking分类器:', sc_concat.score(X_test, y_test))
随机森林: 0.895KNN: 0.9逻辑斯谛回归: 0.855Stacking分类器: 0.91带原始特征的Stacking分类器: 0.905
13.3 提升算法
提升(boosting)算法是另一种集成学习的框架,其基本思路是利用当前模型的误差来调整训练数据的权重,使下一个模型更多关注目前误差较大的部分。假如我们在某一数据集上训练出了模型
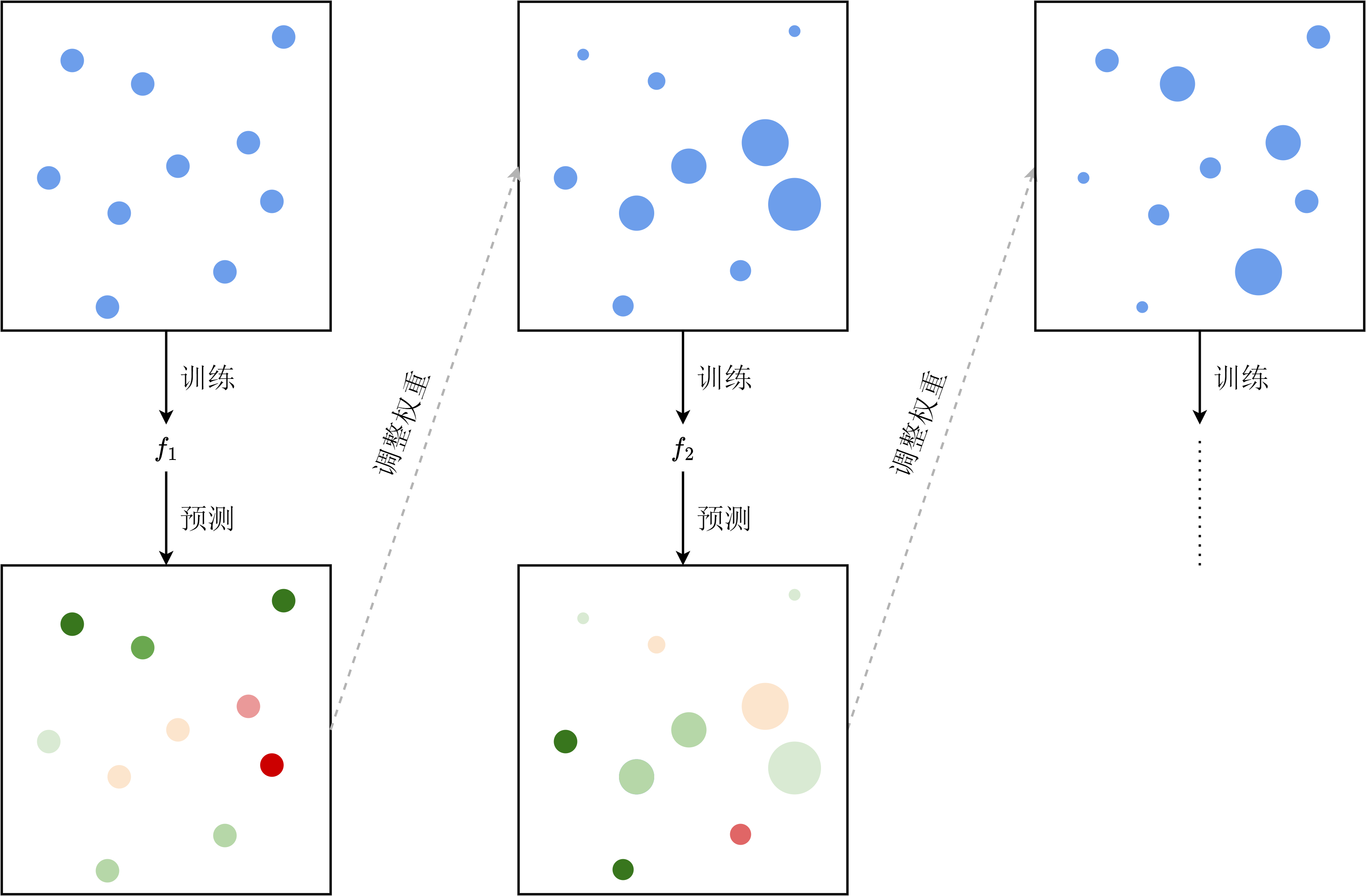
与上面介绍的bagging算法和堆垛算法不同,提升算法用到的各个模型在训练时是串行的。这是因为前两种框架中的子模型互相独立,其训练互不干扰,可以并行训练。而提升算法则在一系列模型中用前一个模型的偏差来调整下一个模型训练集的权重,因此这些模型的训练必须由前到后依次进行。
提升算法的框架中有几个关键问题没有给出确定的答案,分别是如何计算偏差、如何通过偏差计算样本权重、以及如何将得到的各个较弱的学习器结合。这些问题的不同解决方式就导出了不同的提升算法,如适应提升(adaptive boosting,AdaBoost)、逻辑提升(logit boosting)和梯度提升(gradient boosting)等。下面,我们来详细讲解AdaBoost和梯度提升算法,以及梯度提升在决策树上的应用梯度提升决策树(gradient boost decision tree,GBDT)。
13.3.1 适应提升
我们先来考虑提升框架的基本模型。由于各个弱学习器的组合方式是加权平均,我们可以用加性模型(additive model)来表示强学习器:
其中,
来优化
从上式可以看出,两者只差了一个变换
回到AdaBoost上,我们再来推导如何从分类器的预测
当损失函数最小时,其对
解得:
其中,
要优化诸如AdaBoost的加性模型,我们有许多方法。记
对于二分类问题,我们假设每个弱学习器
其中,
对于
注意到
式中,
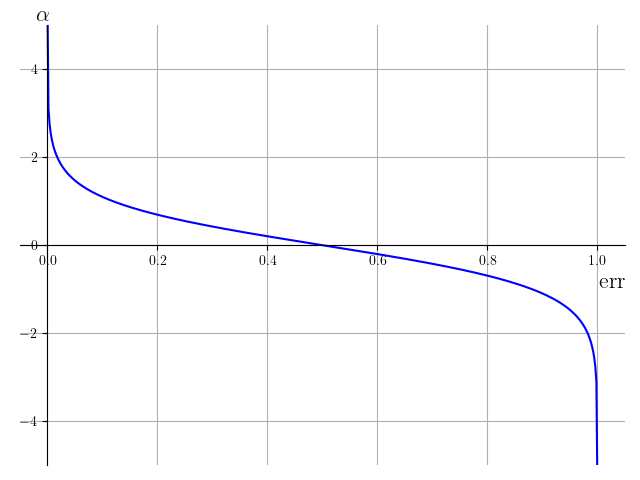
对于
假设分类错误率小于
由于我们考虑的是
综上所述,AdaBoost算法的过程如下:
- 初始化,设数据集大小为
,为所有样本赋予相同的权重 。 - 开始迭代
:
3.
上述AdaBoost算法由于弱分类器
3'.
这一算法的可扩展性相比于离散AdaBoost有了进一步的提升,称为实适应提升(real AdaBoost)算法
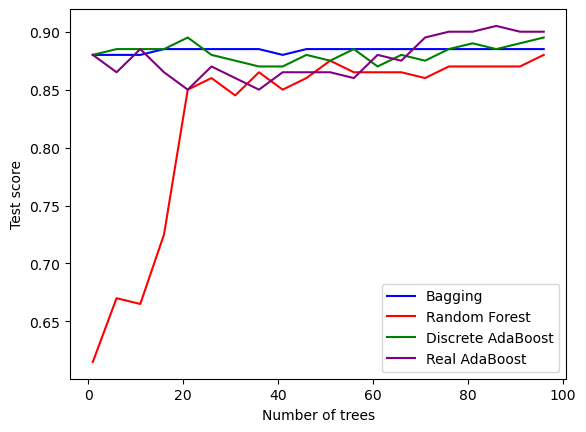
这里,我们不再手动实现AdaBoost算法,而是直接使用sklearn库中的工具,比较其与bagging算法和随机森林算法的效果。其中,所有算法的弱分类器都采用深度为
from sklearn.ensemble import AdaBoostClassifier# 初始化stumpstump = DTC(max_depth=1, min_samples_leaf=1, random_state=0)# 弱分类器个数M = np.arange(1, 101, 5)bg_score = []rf_score = []dsc_ada_score = []real_ada_score = []plt.figure()with tqdm(M) as pbar:for m in pbar:# bagging算法bc = BaggingClassifier(base_estimator=stump,n_estimators=m, random_state=0)bc.fit(X_train, y_train)bg_score.append(bc.score(X_test, y_test))# 随机森林算法rfc = RandomForestClassifier(n_estimators=m, max_depth=1,min_samples_leaf=1, random_state=0)rfc.fit(X_train, y_train)rf_score.append(rfc.score(X_test, y_test))# 离散 AdaBoost,SAMME是分步加性模型(stepwise additive model)的缩写dsc_adaboost = AdaBoostClassifier(base_estimator=stump,n_estimators=m, algorithm='SAMME', random_state=0)dsc_adaboost.fit(X_train, y_train)dsc_ada_score.append(dsc_adaboost.score(X_test, y_test))# 实 AdaBoost,SAMME.R表示弱分类器输出实数real_adaboost = AdaBoostClassifier(base_estimator=stump,n_estimators=m, algorithm='SAMME.R', random_state=0)real_adaboost.fit(X_train, y_train)real_ada_score.append(real_adaboost.score(X_test, y_test))# 绘图plt.plot(M, bg_score, color='blue', label='Bagging')plt.plot(M, rf_score, color='red', label='Random Forest')plt.plot(M, dsc_ada_score, color='green', label='Discrete AdaBoost')plt.plot(M, real_ada_score, color='purple', label='Real AdaBoost')plt.xlabel('Number of trees')plt.ylabel('Test score')plt.legend()plt.show()
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:12<00:00, 1.56it/s]
小故事: 集成学习的思想来自于1989年哈佛大学的莱斯利·瓦利安特(Leslie Valiant)和迈克尔·卡恩斯(Michael Kearns)提出的问题,其大意是:如果在某一问题上已有一个比随机方法好、但是仍然较弱的学习算法,能否保证一定存在很强的学习算法?这一反直觉的问题在1990年由夏皮尔给出了回答,他证明总可以通过不断让新的弱学习器关注当前模型的弱点,将弱学习器组合起来得到强学习器。1995年,约夫·弗雷德(Yoav Freund)改进了夏皮尔的算法,并在1996年和夏皮尔共同提出了里程碑式的集成学习算法AdaBoost。由AdaBoost开始衍生出的一大类提升算法,目前是机器学习领域集成学习方法的绝对主流。与此同时,利奥·布雷曼(Leo Breiman)在1994年提出了bagging算法,何天琴(Tin Kam Ho)于1995年开创了随机森林,而布雷曼在2001年进一步发展和完善了随机森林算法。
由于AdaBoost的非凡表现,1996年开始,不断有学者尝试从数学上分析这一算法,给出泛化误差的理论解释和上界。最初,大家认为与支持向量机相同,AdaBoost的关键在于最大化了最小间隔。但是1999年,布雷曼从最小间隔出发,提出的Arc-gv算法却在比AdaBoost最小间隔更大的情况下泛化误差也更大,这一实验结果无疑给了最小间隔理论沉重的打击。2006年,夏皮尔和列夫·雷津(Lev Reyzin)发现了布雷曼实验中的漏洞,得出了与其相反的结论。随后,高尉和周志华在2013年证明,AdaBoost的关键在于使平均间隔最大的同时使间隔方差最小。直到2019年,艾伦·格隆德(Allan Grønlund)等人最终给出了与下界相匹配的泛化误差上界,解决了AdaBoost的理论问题。
13.3.2 梯度提升
我们可以换一个视角来考虑加性模型的优化过程。考虑连续的回归问题,和实AdaBoost一样将弱学习器的权重与学习器本身合并,记
简单起见,记
这里我们以MSE损失为例来进一步说明。对于MSE损失,
如果把
做一步梯度下降得到
其中
因此,我们可以通过求损失函数在第
如果我们保留一阶近似,就得到:
这时,如果寻找使
这样,我们就得到了和上面仿照梯度下降思路写出的相同的求解公式。并且泰勒展开的思路也提示我们,
梯度提升算法一般要求各个弱学习器的模型一致,实践中通常与决策树相结合,组成梯度提升决策树
这里把每个样本的损失函数从期望改为相加,本质上没有区别。此外,由于前
其中,
为了进一步简化上式,使其可以求解,我们考虑决策树模型
式中,
我们将
其中
当决策树对样本的分类方式
其对应的损失函数的最小值为:
上式是在我们固定决策树结构的前提下求出的损失函数的最小值,那么对于某个结构的决策树,无论其叶节点的值怎样优化,其损失函数都无法比上式更低了。因此,上式可以用来评价一个决策树结构的好坏。与决策树一章中的做法相同,在分裂节点前,我们首先计算上式在分裂前后的值,只有当分裂后的最小损失比分裂前的最小损失更低时,我们才会执行分裂操作。XGBoost算法通过如上的步骤设计的损失函数,往往能使决策树的结构比用其他损失函数构造出的更优,因此取得了较好的均衡表现。在实践中,XGBoost还进行了许多算法和工程上的优化,例如随机森林的特征采样、缓存优化、并行优化等,大大提升了它在大规模数据集上的性能。
本章最后,我们用xgboost库来展示XGBoost算法的表现,并和上文介绍的其他算法进行对比。为了体现各个算法的水平,我们用sklearn中的make_friedman1工具生成一个更复杂的非线性回归数据集进行测试。设输入样本为
式中的
# 安装并导入xgboost库!pip install xgboostimport xgboost as xgbfrom sklearn.datasets import make_friedman1from sklearn.neighbors import KNeighborsRegressorfrom sklearn.linear_model import LinearRegressionfrom sklearn.tree import DecisionTreeRegressorfrom sklearn.ensemble import BaggingRegressor, RandomForestRegressor, \StackingRegressor, AdaBoostRegressor# 生成回归数据集reg_X, reg_y = make_friedman1(n_samples=2000, # 样本数目n_features=100, # 特征数目noise=0.5, # 噪声的标准差random_state=0 # 随机种子)# 划分训练集与测试集reg_X_train, reg_X_test, reg_y_train, reg_y_test = \train_test_split(reg_X, reg_y, test_size=0.2, random_state=0)
def rmse(regressor):# 计算regressor在测试集上的RMSEy_pred = regressor.predict(reg_X_test)return np.sqrt(np.mean((y_pred - reg_y_test) ** 2))# XGBoost回归树xgbr = xgb.XGBRegressor(n_estimators=100, # 弱分类器数目max_depth=1, # 决策树最大深度learning_rate=0.5, # 学习率gamma=0.0, # 对决策树叶节点数目的惩罚系数,当弱分类器为stump时不起作用reg_lambda=0.1, # L2正则化系数subsample=0.5, # 与随机森林类似,表示采样特征的比例objective='reg:squarederror', # MSE损失函数eval_metric='rmse', # 用RMSE作为评价指标random_state=0 # 随机种子)xgbr.fit(reg_X_train, reg_y_train)print(f'XGBoost:{rmse(xgbr):.3f}')# KNN回归knnr = KNeighborsRegressor(n_neighbors=5).fit(reg_X_train, reg_y_train)print(f'KNN:{rmse(knnr):.3f}')# 线性回归lnr = LinearRegression().fit(reg_X_train, reg_y_train)print(f'线性回归:{rmse(lnr):.3f}')# baggingstump_reg = DecisionTreeRegressor(max_depth=1,min_samples_leaf=1, random_state=0)bcr = BaggingRegressor(base_estimator=stump_reg,n_estimators=100, random_state=0)bcr.fit(reg_X_train, reg_y_train)print(f'Bagging:{rmse(bcr):.3f}')# 随机森林rfr = RandomForestRegressor(n_estimators=100, max_depth=1,max_features='sqrt', random_state=0)rfr.fit(reg_X_train, reg_y_train)print(f'随机森林:{rmse(rfr):.3f}')# 堆垛,默认元学习器为带L2正则化约束的线性回归stkr = StackingRegressor(estimators=[('knn', knnr),('ln', lnr),('rf', rfr)])stkr.fit(reg_X_train, reg_y_train)print(f'Stacking:{rmse(stkr):.3f}')# 带有输入特征的堆垛stkr_pt = StackingRegressor(estimators=[('knn', knnr),('ln', lnr),('rf', rfr)], passthrough=True)stkr_pt.fit(reg_X_train, reg_y_train)print(f'带输入特征的Stacking:{rmse(stkr_pt):.3f}')# AdaBoost,回归型AdaBoost只有连续型,没有离散型abr = AdaBoostRegressor(base_estimator=stump_reg, n_estimators=100,learning_rate=1.5, loss='square', random_state=0)abr.fit(reg_X_train, reg_y_train)print(f'AdaBoost:{rmse(abr):.3f}')
XGBoost:1.652KNN:4.471线性回归:2.525Bagging:4.042随机森林:4.514Stacking:2.231带输入特征的Stacking:2.288AdaBoost:3.116
13.4 本章小结
本章主要介绍了集成学习的基本概念和3类不同的集成学习框架。其中,自举聚合和集成学习器两种框架利用模型之间取长补短的思想进行提升,各个模型之间互不干扰,可以并行训练;而提升框架希望模型组成序列依次进行优化,让后一个模型关注当前模型的缺陷和误差点,需要串行训练,但也更有针对性。各个框架各有优劣,面对不同的任务和条件限制时,我们应当根据具体情况选择合适的集成学习算法。
在最后的比较中,XGBoost算法取得了最好的效果。事实上,XGBoost算法的参数对其表现有非常关键的影响。上面只列出了算法的部分参数,读者可以查阅官方文档和相关教程,了解更多参数的含义,并观察参数改变时训练结果的变化。此外,xgboost库对GPU并行计算做了优化,有计算资源的读者还可以尝试在GPU和更大的数据集上运行XGBoost与其他算法,比较它们的运行速度。
由于复杂度的关系,本章选取的学习器中不包含神经网络模型。但随着深度学习的发展,集成学习在神经网络上的应用也越来越受重视。不同的神经网络模型由于其结构不同,依然可以通过取长补短的思想集成得到更好的模型。此外,集成学习还发展出了神经网络的自集成、集成结构自动搜索等多个研究领域。在卷积神经网络一章的最后,我们曾提到对大模型进行微调逐渐成为现在的主流。由于训练更好的大模型十分困难,而并行的集成学习不需要重新训练底层的模型,在实际应用中,人们还会将不同的大模型进行集成,从而快速达到比单一大模型更好的效果。
习题
以下关于集成学习的说法不正确的是: A. 在集成学习中,我们可以为数据空间的不同区域使用不同的预测模型,再将预测结果进行组合。 B. 一组预测模型可以有多种方式进行集成学习。 C. 有效的集成学习需要集合中的模型具有单一性,最好将同一类型的预测模型结合起来。 D. 训练集成模型时,单个模型的参数不会随之更新。
以下关于提升算法的说法正确的是: A. AdaBoost算法中,
绝对值越小的模型权重绝对值越大,在集成模型中占有主导地位。 B. AdaBoost算法中,需要按照之前学习器的结果对训练数据进行加权采样。 C. GBDT算法用到了“梯度反方向是函数值下降最快方向”的思想。 D. GBDT的正则化约束只考虑了叶节点的数目。 由基础学习器提取特征后再供给元学习器进一步学习,这一特征提取的思想在前面哪些章节也出现过?为什么合适的特征提取往往能提升算法的表现?
基于本章代码,尝试非线性的元分类器,如神经网络和决策树,观察原始数据拼接到新数据上的模型预测性能的改变。
在提升算法中,弱学习器的数量越多,元学习器的效果是否一定越好?调整AdaBoost和GBDT代码中弱学习器的数量,验证你的想法。
基于xgboost库,对于本章涉及的回归任务,调试树的数量上限、每棵树的深度上限、学习率,观察其训练模型性能的改变,讨论是大量较浅的树组成的GBDT模型更强,还是少量的较深的树组成的GBDT模型更强。
参考文献
[1] AdaBoost的目标函数论文:Schapire R E, Singer Y. Improved boosting algorithms using confidence-rated predictions[C]//Proceedings of the eleventh annual conference on Computational learning theory. 1998: 80-91.
[2] 实AdaBoost论文:Friedman J, Hastie T, Tibshirani R. Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors)[J]. The annals of statistics, 2000, 28(2): 337-407.
[3] GBDT论文:Friedman J H. Greedy function approximation: a gradient boosting machine[J]. Annals of statistics, 2001: 1189-1232.
[4] XGBoost论文:Chen T, Guestrin C. Xgboost: A scalable tree boosting system[C]//Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016: 785-794.
[5] Friedman一号数据集的论文:Friedman J H. Multivariate adaptive regression splines[J]. The annals of statistics, 1991, 19(1): 1-67.