第 14 章 k均值聚类
本章开始我们讲解无监督学习算法。在之前的章节中,我们给模型的任务通常是找到样本
本章我们将要讲解的k均值(k-means)聚类算法就是一个无监督学习算法。它的目标是将数据集中的样本根据其特征分为几个类,使得每一类内部样本的特征都尽可能相近,这样的任务通常称为聚类任务。作为最简单的聚类算法,k均值算法在现实中有广泛的应用。下面,我们就来详细讲解k均值算法的原理。
14.1 k均值聚类的原理
假设空间中有一些点,聚类问题的目标就是将这些点按距离分成数类。设数据集
当然,仅仅随机选取中心点还不够,我们还要继续进行优化,尽可能减小类内的点到中心点距离。将数据集中所有点到其对应中心距离之和作为损失函数,得到:
既然在初始时,各个类的中心点
如果我们用欧氏距离的平方
令该偏导数为零,就得到最优的中心点为:
该式表明,最优中心点就是
14.2 动手实现k均值算法
下面,我们用一个简单的平面点集kmeans_data.csv来展示k均值聚类算法的效果。首先,我们加载数据集并可视化。数据集中每行包含两个值
import numpy as npimport matplotlib.pyplot as pltdataset = np.loadtxt('kmeans_data.csv', delimiter=',')print('数据集大小:', len(dataset))
数据集大小: 80
# 绘图函数def show_cluster(dataset, cluster, centroids=None):# dataset:数据# centroids:聚类中心点的坐标# cluster:每个样本所属聚类# 不同种类的颜色,用以区分划分的数据的类别colors = np.array(['blue', 'red', 'green', 'purple'])# 画出所有样例plt.scatter(dataset[:, 0], dataset[:, 1], color=colors[cluster])# 画出中心点if centroids is not None:K = len(centroids)plt.scatter(centroids[:, 0], centroids[:, 1],color=colors[:K], marker='+', s=150)plt.show()# 初始时不区分类别show_cluster(dataset, np.zeros(len(dataset), dtype=int))
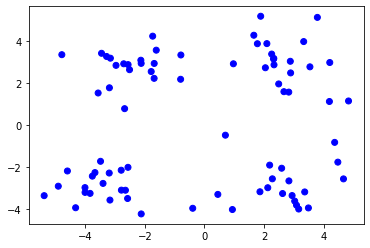
对于简单的k均值算法,初始的中心点是从现有样本中随机选取的,我们将其实现如下。
def random_init(dataset, K):# 随机选取是不重复的idx = np.random.choice(np.arange(len(dataset)), size=K, replace=False)return dataset[idx]
接下来,我们用欧氏距离作为标准,实现上面描述的迭代过程。由于数据集比较简单,我们将迭代的终止条件设置为所有点的分类都不再变化。对于更复杂的数据集,这一条件很可能无法使迭代终止,从而需要我们控制最大迭代次数,或者设置允许类别变动的点的比例等等。
def Kmeans(dataset, K, init_cent):# dataset:数据集# K:目标聚类数# init_cent:初始化中心点的函数centroids = init_cent(dataset, K)cluster = np.zeros(len(dataset), dtype=int)changed = True# 开始迭代itr = 0while changed:changed = Falseloss = 0for i, data in enumerate(dataset):# 寻找最近的中心点dis = np.sum((centroids - data) ** 2, axis=-1)k = np.argmin(dis)# 更新当前样本所属的聚类if cluster[i] != k:cluster[i] = kchanged = True# 计算损失函数loss += np.sum((data - centroids[k]) ** 2)# 绘图print(f'Iteration {itr}, Loss {loss:.3f}')show_cluster(dataset, cluster, centroids)# 更新中心点for i in range(K):centroids[i] = np.mean(dataset[cluster == i], axis=0)itr += 1return centroids, cluster
最后,我们观察k均值算法在上面的数据集上聚类的过程。根据上面的可视化结果,我们大概可以看出有4个聚类,因此设定
np.random.seed(0)cent, cluster = Kmeans(dataset, 4, random_init)
Iteration 0, Loss 711.345
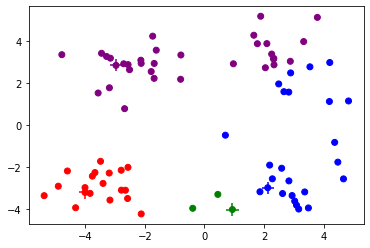
Iteration 1, Loss 409.497
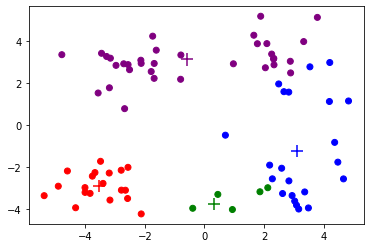
Iteration 2, Loss 395.266
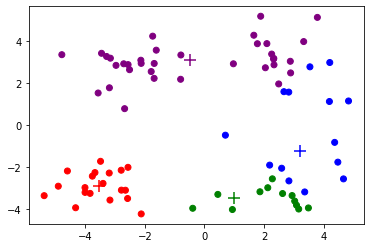
Iteration 3, Loss 346.070
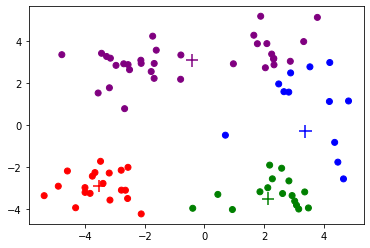
Iteration 4, Loss 294.243
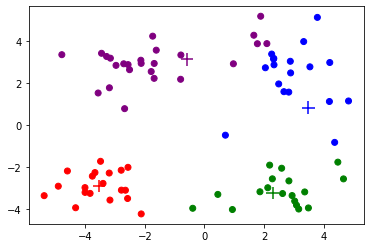
Iteration 5, Loss 178.808
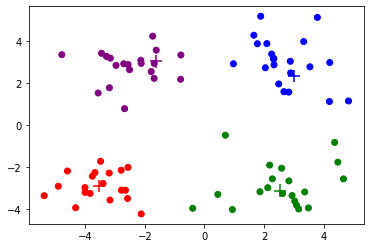
Iteration 6, Loss 151.089
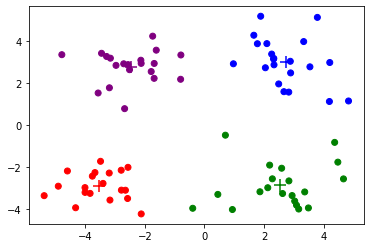
14.3 k-means++
上面的分类结果与我们的主观感受区别不大。但是,k均值算法对初始选择的聚类中心非常敏感,且极易收敛到局部最小值,因此不同的中心选择可能导致完全不同的划分。通常来说,我们可以用不同的随机种子选择多组初值,最终挑出划分最好的那一个。但是,当聚类个数和数据量较大时,k均值算法运行需要的时间很长,反复调整随机种子也很不方便。因此,k-means++算法
首先,k-means++算法从所有样本中随机选取一个点当作第一个聚类的中心点。直观上来讲,我们希望初始的中心点尽可能散开。因此在选择接下来的中心点时,该算法会将样本到当前中心点的距离也纳入考量。设目前已有
上式的分母是在整个数据集上进行的求和,使所有样本被选为中心点的概率值和为
下面,我们来实现k-means++的初始化函数。
def kmeanspp_init(dataset, K):# 随机第一个中心点idx = np.random.choice(np.arange(len(dataset)))centroids = dataset[idx][None]for k in range(1, K):d = []# 计算每个点到当前中心点的距离for data in dataset:dis = np.sum((centroids - data) ** 2, axis=-1)# 取最短距离的平方d.append(np.min(dis) ** 2)# 归一化d = np.array(d)d /= np.sum(d)# 按概率选取下一个中心点cent_id = np.random.choice(np.arange(len(dataset)), p=d)cent = dataset[cent_id]centroids = np.concatenate([centroids, cent[None]], axis=0)return centroids
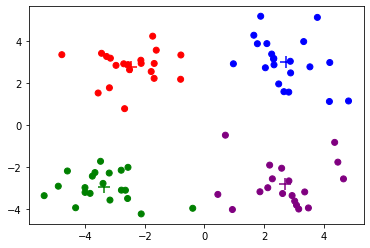
我们已经预留了初始化函数的接口,只需要将参数从random_init替换为kmeanspp_init就可以测试k-means++算法的表现了。从绘制的迭代中间结果可以明显看出,用k-means++算法选择的初始中心点互相之间的距离非常远,从而收敛速度也要快很多。读者可以修改随机种子,观察随机初始化和k-means++初始化对随机种子的敏感程度。
cent, cluster = Kmeans(dataset, 4, kmeanspp_init)
Iteration 0, Loss 373.941
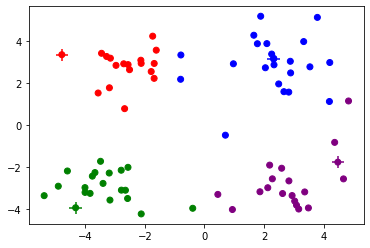
Iteration 1, Loss 158.147
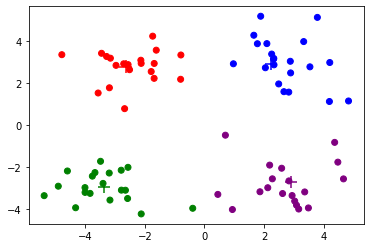
Iteration 2, Loss 151.273
14.4 本章小结
本章主要介绍了k均值聚类算法和其改进版k-means++。k均值算法由于其简单易用,应用非常广泛。然而,它也高度依赖于初始中心和距离函数的选取。上面的k-means++就是在初始中心点选取的方式上做了改进。对于距离函数来说,它起到判断哪些样本之间的距离较近的关键作用,因此也要随数据集的特征而灵活调整。在上面的平面点集任务中,我们选用了最简单的欧氏距离。而当数据的特征维度较高时,简单的欧氏距离会面临维数灾难问题。简单来说,在高维空间中,数据点会变得越来越稀疏,任意两个数据点之间的欧氏距离都差别不大,欧氏距离失去了判断相似度的功能。因此,当数据的特征维度更高、关系更复杂的时候,距离函数需要精心设计,甚至要通过神经网络训练得到。因此,k均值聚类算法通常不会作为复杂聚类任务的第一步,而是在其他算法挑选出数据的关键特征、得到合适的距离函数后,再进行最后的聚类工作。
网站Cartography Playground给出了在平面点集上应用k均值算法的动画演示和结果,感兴趣的读者还可以自行调整数据集,观察迭代过程中中心点和聚类的变化,加深对k均值算法的理解。
习题
k均值算法收敛得到的解一定是局部最优吗?一定是全局最优吗? A. 是 B. 不是
如果设定的
值比数据中实际的类别要少,会造成什么情况?是否有办法在不知道数据包含几类的情况下,选出合适的 值? k均值算法的结果及其依赖于初始中心的选取,从而对随机种子非常敏感。试构造一个数据集,在
的情况下,存在至少两组 K 均值算法可能收敛到的聚类中心,且数据的分类不同。如果换成k-means++算法,在该数据集上收敛的结果是否唯一? 除了k-means++以外,k均值算法还有一种改进,称为二分k均值。该算法首先将所有数据看作一类。接下来每次迭代中,找到类内部所有点距离之和
最大的类,再将该类分成两个使得类内距离之和下降最多的子类。如此循环,直到类的数量达到预先指定的
设计一种新的距离度量函数,实现基于该度量函数的k-means和k-means++,并在14.2节中的数据集上测试。
查阅相关文献,学习并实现DBSCAN聚类算法
,并和k-means、k-means++对比。
参考文献
[1] k-means++论文:Arthur D, Vassilvitskii S. k-means++: The advantages of careful seeding[R]. Stanford, 2006.
[2] DBSCAN论文:Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//kdd. 1996, 96(34): 226-231.