第 7 章 双线性模型
从本章开始,我们介绍参数化模型中的非线性模型。在前几章中,我们介绍了线性回归与逻辑斯谛回归模型。这两个模型都有一个共同的特征:包含线性预测因子
双线性模型虽然名称中包含“线性模型”,但并不属于线性模型或广义线性模型,其正确的理解应当是“双线性”模型。在数学中,双线性的含义为,二元函数固定任意一个自变量时,函数关于另一个自变量线性。具体来说,二元函数
最简单的双线性函数的例子是向量内积
后两条性质由对称性,显然也是成立的。而向量的加法就不是双线性函数。虽然加法满足第 1、3 条性质,但对第 2 条,如果
与线性模型类似,双线性模型并非指模型整体具有双线性性质,而是指其包含双线性因子。该特性赋予模型拟合一些非线性数据模式的能力,从而得到更加精准预测性能。接下来,我们以推荐系统场景为例,介绍两个基础的双线性模型:矩阵分解模型和因子分解机。
7.1 矩阵分解
矩阵分解(matrix factorization,MF)
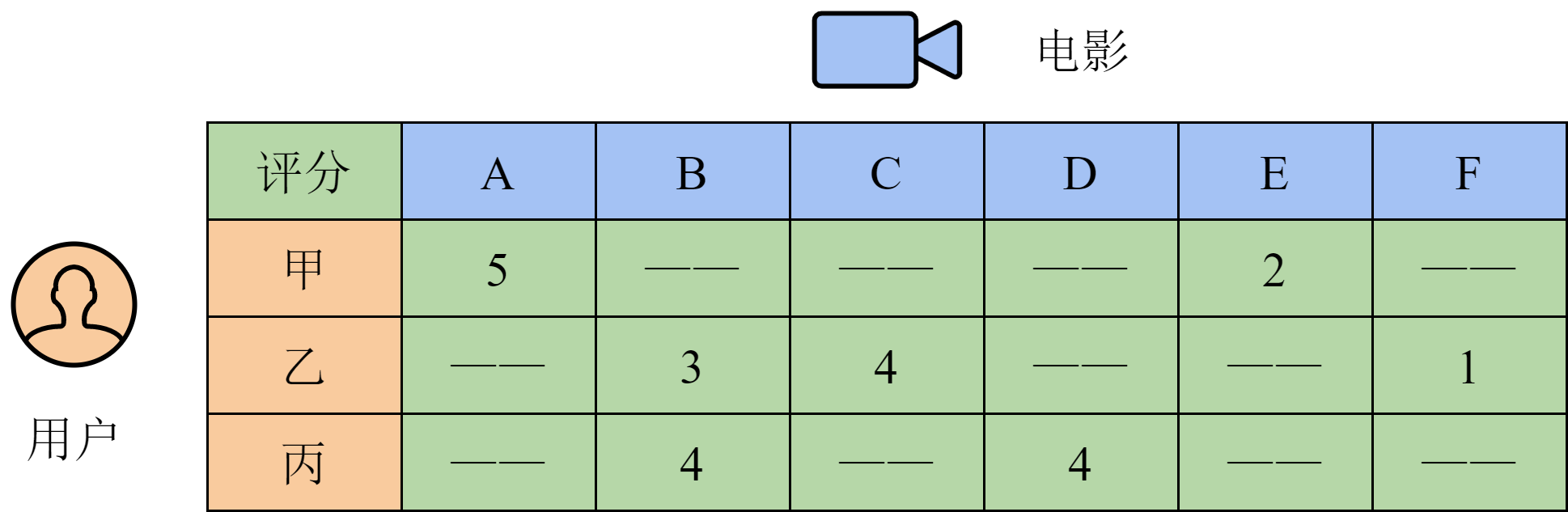
我们继续从生活经验出发来思考这一问题。假设某用户为一部电影打了高分,那么可以合理猜测,该用户喜欢这部电影的某些特征。例如,电影的类型是悬疑、爱情、战争或是其他种类;演员、导演和出品方分别是哪些;叙述的故事发生在什么年代;时长是多少,等等。假如我们有一个电影特征库,可以将每部电影用一个特征向量表示。向量的每一维代表一种特征,值代表电影具有这一特征的程度。同时,我们还可以构建一个用户画像库,包含每个用户更偏好哪些类型的特征,以及偏好的程度。假设特征的个数是
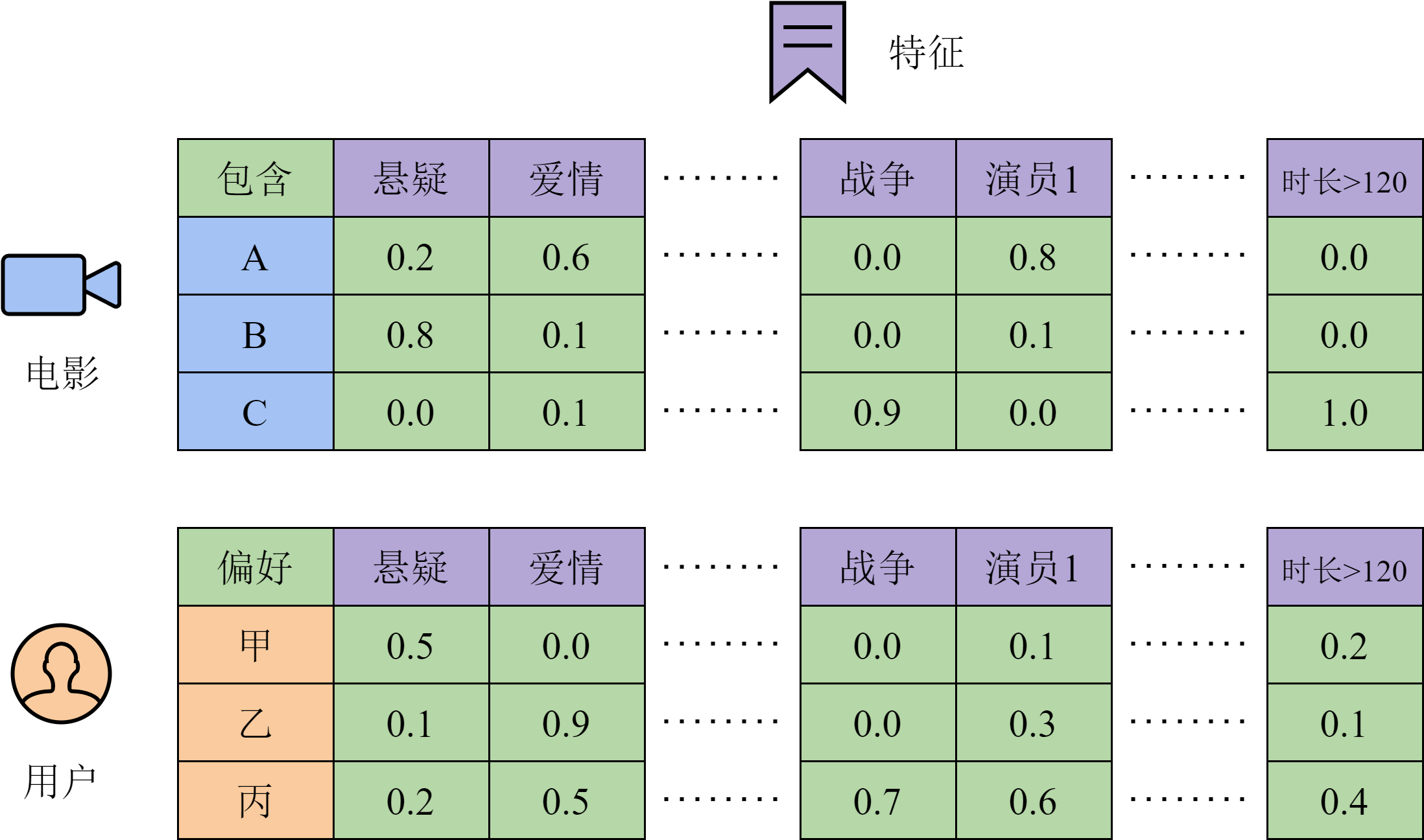
需要说明的是,我们实际上分解出的矩阵只是某种交互结果背后的隐变量,并不一定对应真实的特征。这样,我们就把一个用户与电影交互的矩阵拆分成了用户、电影两个矩阵,并且这两个矩阵中包含了更多的信息。最后,用这两个矩阵的乘积
小故事:矩阵分解和下面要介绍的因子分解机都属于推荐系统(recommender system)领域的算法。我们在日常使用软件、浏览网站的时候,软件或网站会记录下来我们感兴趣的内容,并在接下来更多地为我们推送同类型的内容。例如,如果我们在购物网站上浏览过牙刷,它就可能再给我们推荐牙刷、毛巾、脸盆等等相关性比较大的商品,这就是推荐系统的作用。推荐系统希望根据用户的特征、商品的特征、用户和商品的交互历史,为用户做出更符合个人喜好的个性化推荐,提高用户的浏览体验,同时为公司带来更高的经济效益。
机器学习界开始大量关注推荐系统任务源自美国奈飞电影公司(Netflix)于 2006 年举办的世界范围的推荐系统算法大赛。该比赛旨在探寻一种算法能更加精确地预测 48 万名用户对 1.7 万部电影的打分,如果某个参赛队伍给出的评分预测精度超过了基线算法 10%,就可以获得 100 万美元的奖金。该竞赛在 1 年来吸引了来自全球 186 个国家的超过 4 万支队伍的参加,经过 3 年的“马拉松”竞赛,最终由一支名为 BellKor's Pragmatic Chaos 的联合团队摘得桂冠。而团队中时任雅虎研究员的耶胡达·科伦(Yehuda Koren)则在后来成为了推荐系统领域最为著名的科学家之一,他使用的基于矩阵分解的双线性模型则成为了那个时代推荐系统的主流模型[1]。
实际上,我们通常能获取到的并不是
既然 MF 的目标是通过特征还原评分矩阵
式中,
再加入对
需要注意,这里的
可以发现,上面
7.2 动手实现矩阵分解
下面,我们来动手实现矩阵分解模型。我们选用的数据集是推荐系统中的常用数据集 MovieLens,其包含从电影评价网站 MovieLens 中收集的真实用户对电影的打分信息。简单起见,我们采用其包含来自 943 个用户对 1682 部电影的 10 万条样本的版本 MovieLens-100k。我们对原始的数据进行了一些处理,现在数据集的每一行有 3 个数,依次表示用户编号
表 7-1 MovieLens 数据集示例
| 用户编号 | 电影编号 | 评分 |
|---|---|---|
| 196 | 242 | 3 |
| 186 | 302 | 3 |
| 22 | 377 | 1 |
import numpy as npimport matplotlib.pyplot as pltfrom tqdm import tqdm # 进度条工具data = np.loadtxt('movielens_100k.csv', delimiter=',', dtype=int)print('数据集大小:', len(data))# 用户和电影都是从1开始编号的,我们将其转化为从0开始data[:, :2] = data[:, :2] - 1# 计算用户和电影数量users = set()items = set()for i, j, k in data:users.add(i)items.add(j)user_num = len(users)item_num = len(items)print(f'用户数:{user_num},电影数:{item_num}')# 设置随机种子,划分训练集与测试集np.random.seed(0)ratio = 0.8split = int(len(data) * ratio)np.random.shuffle(data)train = data[:split]test = data[split:]# 统计训练集中每个用户和电影出现的数量,作为正则化的权重user_cnt = np.bincount(train[:, 0], minlength=user_num)item_cnt = np.bincount(train[:, 1], minlength=item_num)print(user_cnt[:10])print(item_cnt[:10])# 用户和电影的编号要作为下标,必须保存为整数user_train, user_test = train[:, 0], test[:, 0]item_train, item_test = train[:, 1], test[:, 1]y_train, y_test = train[:, 2], test[:, 2]
数据集大小: 100000用户数:943,电影数:1682[215 47 42 19 139 170 320 47 18 156][371 109 70 172 70 21 308 158 240 68]
接下来,我们将 MF 模型定义成类,在其中实现梯度计算方法。根据上面的推导,模型的参数是用户喜好
class MF:def __init__(self, N, M, d):# N是用户数量,M是电影数量,d是特征维度# 定义模型参数self.user_params = np.ones((N, d))self.item_params = np.ones((M, d))def pred(self, user_id, item_id):# 预测用户user_id对电影item_id的打分# 获得用户偏好和电影特征user_param = self.user_params[user_id]item_param = self.item_params[item_id]# 返回预测的评分rating_pred = np.sum(user_param * item_param, axis=1)return rating_preddef update(self, user_grad, item_grad, lr):# 根据参数的梯度更新参数self.user_params -= lr * user_gradself.item_params -= lr * item_grad
下面定义训练函数,以 SGD 算法对 MF 模型的参数进行优化。对于回归任务来说,我们仍然以 MSE 作为损失函数,RMSE 作为的评价指标。在训练的同时,我们将其记录下来,供最终绘制训练曲线使用。
def train(model, learning_rate, lbd, max_training_step, batch_size):train_losses = []test_losses = []batch_num = int(np.ceil(len(user_train) / batch_size))with tqdm(range(max_training_step * batch_num)) as pbar:for epoch in range(max_training_step):# 随机梯度下降train_rmse = 0for i in range(batch_num):# 获取当前批量st = i * batch_sizeed = min(len(user_train), st + batch_size)user_batch = user_train[st: ed]item_batch = item_train[st: ed]y_batch = y_train[st: ed]# 计算模型预测y_pred = model.pred(user_batch, item_batch)# 计算梯度P = model.user_paramsQ = model.item_paramserrs = y_batch - y_predP_grad = np.zeros_like(P)Q_grad = np.zeros_like(Q)for user, item, err in zip(user_batch, item_batch, errs):P_grad[user] = P_grad[user] - err * Q[item] + lbd * P[user]Q_grad[item] = Q_grad[item] - err * P[user] + lbd * Q[item]model.update(P_grad / len(user_batch), Q_grad / len(user_batch), learning_rate)train_rmse += np.mean(errs ** 2)# 更新进度条pbar.set_postfix({'Epoch': epoch,'Train RMSE': f'{np.sqrt(train_rmse / (i + 1)):.4f}','Test RMSE': f'{test_losses[-1]:.4f}' if test_losses else None})pbar.update(1)# 计算测试集上的RMSEtrain_rmse = np.sqrt(train_rmse / len(user_train))train_losses.append(train_rmse)y_test_pred = model.pred(user_test, item_test)test_rmse = np.sqrt(np.mean((y_test - y_test_pred) ** 2))test_losses.append(test_rmse)return train_losses, test_losses
最后,我们定义超参数,并实现 MF 模型的训练部分,并将损失随训练的变化曲线绘制出来。
# 超参数feature_num = 16 # 特征数learning_rate = 0.1 # 学习率lbd = 1e-4 # 正则化强度max_training_step = 30batch_size = 64 # 批量大小# 建立模型model = MF(user_num, item_num, feature_num)# 训练部分train_losses, test_losses = train(model, learning_rate, lbd,max_training_step, batch_size)plt.figure()x = np.arange(max_training_step) + 1plt.plot(x, train_losses, color='blue', label='train loss')plt.plot(x, test_losses, color='red', ls='--', label='test loss')plt.xlabel('Epoch')plt.ylabel('RMSE')plt.legend()plt.show()
88%|██████████████▉ | 32883/37500 [01:16<00:09, 488.84it/s, Epoch=26, Train RMSE=0.9871, Test RMSE=1.0160]
为了直观地展示模型效果,我们输出一些模型在测试集中的预测结果与真实结果进行对比。上面我们训练得到的模型在测试集上的 RMSE 大概是 1 左右,所以这里模型预测的评分与真实评分大致也差 1。
y_test_pred = model.pred(user_test, item_test)print(y_test_pred[:10]) # 把张量转换为numpy数组print(y_test[:10])
7.3 因子分解机
本节我们介绍推荐系统中用户行为预估的另一个常用模型:因子分解机(factorization machines,FM)
其中,
式中,矩阵
在用向量表示某一事物的离散特征时,一种常用的方法是独热编码(one-hot encoding)。这一方法中,向量的每一维都对应特征的一种取值,样本所具有的特征所在的维度值为 1,其他维度为 0。如图 7-3 所示,某物品的产地是北京、上海、广州、深圳其中之一,为了表示该物品的产地,我们将其编码为 4 维向量,4 个维度依次对应产地北京、上海、广州、深圳。当物品产地为北京时,其特征向量就是

像这样的独热特征向量往往维度非常高,但只有少数几个位置是 1,其他位置都是 0,稀疏程度很高。当我们训练上述的模型时,需要对参数
这时,再对参数
上面的计算过程中,为了简洁,我们采用了不太严谨的写法,当
至此,我们的模型还存在一个问题。双线性模型考虑不同特征之间乘积的做法,虽然提升了模型的能力,但也引入了额外的计算开销。对一个样本来说,线性模型需要计算
在变形的第二步和第三步,我们利用了向量内积的双线性性质,将标量
如果要做分类任务,只需要再加上 softmax 函数即可。
在上面的模型中,我们只考虑了两个特征之间的组合,因此该 FM 也被称为二阶 FM。如果进一步考虑多个特征的组合,如
7.4 动手实现因子分解机
下面,我们来动手实现二阶 FM 模型。本节采用的数据集是为 FM 制作的示例数据集 fm_dataset.csv,包含了某个用户浏览过的商品的特征,以及用户是否点击过这个商品。数据集的每一行包含一个商品,前 24 列是其特征,最后一列是 0 或 1,分别表示用户没有或有点击该商品。我们的目标是根据输入特征预测用户在测试集上的行为,是一个二分类问题。我们先导入必要的模块和数据集并处理数据,将其划分为训练集和测试集。
import numpy as npimport matplotlib.pyplot as pltfrom sklearn import metrics # sklearn中的评价指标函数库from tqdm import tqdm# 导入数据集data = np.loadtxt('fm_dataset.csv', delimiter=',')# 划分数据集np.random.seed(0)ratio = 0.8split = int(ratio * len(data))x_train = data[:split, :-1]y_train = data[:split, -1]x_test = data[split:, :-1]y_test = data[split:, -1]# 特征数feature_num = x_train.shape[1]print('训练集大小:', len(x_train))print('测试集大小:', len(x_test))print('特征数:', feature_num)
训练集大小: 800测试集大小: 200特征数: 24
接下来,我们将 FM 模型定义成类。与 MF 相同,我们在类中实现预测和梯度更新方法。
class FM:def __init__(self, feature_num, vector_dim):# vector_dim代表公式中的k,为向量v的维度self.theta0 = 0.0 # 常数项self.theta = np.zeros(feature_num) # 线性参数self.v = np.random.normal(size=(feature_num, vector_dim)) # 双线性参数self.eps = 1e-6 # 精度参数def _logistic(self, x):# 工具函数,用于将预测转化为概率return 1 / (1 + np.exp(-x))def pred(self, x):# 线性部分linear_term = self.theta0 + x @ self.theta# 双线性部分square_of_sum = np.square(x @ self.v)sum_of_square = np.square(x) @ np.square(self.v)# 最终预测y_pred = self._logistic(linear_term \+ 0.5 * np.sum(square_of_sum - sum_of_square, axis=1))# 为了防止后续梯度过大,对预测值进行裁剪,将其限制在某一范围内y_pred = np.clip(y_pred, self.eps, 1 - self.eps)return y_preddef update(self, grad0, grad_theta, grad_v, lr):self.theta0 -= lr * grad0self.theta -= lr * grad_thetaself.v -= lr * grad_v
对于分类任务,我们仍用 MLE 作为训练时的损失函数。在测试集上,我们采用 AUC 作为评价指标。由于我们在第 6 章中已经动手实现过 AUC,简单起见,这里我们就直接使用 sklearn 中的函数直接计算 AUC。我们用 SGD 进行参数更新,训练完成后,我们把训练过程中的准确率和 AUC 绘制出来。
# 超参数设置,包括学习率、训练轮数等vector_dim = 16learning_rate = 0.01lbd = 0.05max_training_step = 200batch_size = 32# 初始化模型np.random.seed(0)model = FM(feature_num, vector_dim)train_acc = []test_acc = []train_auc = []test_auc = []with tqdm(range(max_training_step)) as pbar:for epoch in pbar:st = 0while st < len(x_train):ed = min(st + batch_size, len(x_train))X = x_train[st: ed]Y = y_train[st: ed]st += batch_size# 计算模型预测y_pred = model.pred(X)# 计算交叉熵损失cross_entropy = -Y * np.log(y_pred) \- (1 - Y) * np.log(1 - y_pred)loss = np.sum(cross_entropy)# 计算损失函数对y的梯度,再根据链式法则得到总梯度grad_y = (y_pred - Y).reshape(-1, 1)# 计算y对参数的梯度# 常数项grad0 = np.sum(grad_y * (1 / len(X) + lbd))# 线性项grad_theta = np.sum(grad_y * (X / len(X) \+ lbd * model.theta), axis=0)# 双线性项grad_v = np.zeros((feature_num, vector_dim))for i, x in enumerate(X):# 先计算sum(x_i * v_i)xv = x @ model.vgrad_vi = np.zeros((feature_num, vector_dim))for s in range(feature_num):grad_vi[s] += x[s] * xv - (x[s] ** 2) * model.v[s]grad_v += grad_y[i] * grad_vigrad_v = grad_v / len(X) + lbd * model.vmodel.update(grad0, grad_theta, grad_v, learning_rate)pbar.set_postfix({'训练轮数': epoch,'训练损失': f'{loss:.4f}','训练集准确率': train_acc[-1] if train_acc else None,'测试集准确率': test_acc[-1] if test_acc else None})# 计算模型预测的准确率和AUC# 预测准确率,阈值设置为0.5y_train_pred = (model.pred(x_train) >= 0.5)acc = np.mean(y_train_pred == y_train)train_acc.append(acc)auc = metrics.roc_auc_score(y_train, y_train_pred) # sklearn中的AUC函数train_auc.append(auc)y_test_pred = (model.pred(x_test) >= 0.5)acc = np.mean(y_test_pred == y_test)test_acc.append(acc)auc = metrics.roc_auc_score(y_test, y_test_pred)test_auc.append(auc)print(f'测试集准确率:{test_acc[-1]},\t测试集AUC:{test_auc[-1]}')
100%|█| 200/200 [00:43<00:00, 4.61it/s, 训练轮数=199, 训练损失=11.3006, 训练集准确率=0.816, 测试集准确率=0.200 [00:00<?, ?it/s]测试集准确率:0.79, 测试集AUC:0.7201320910484726
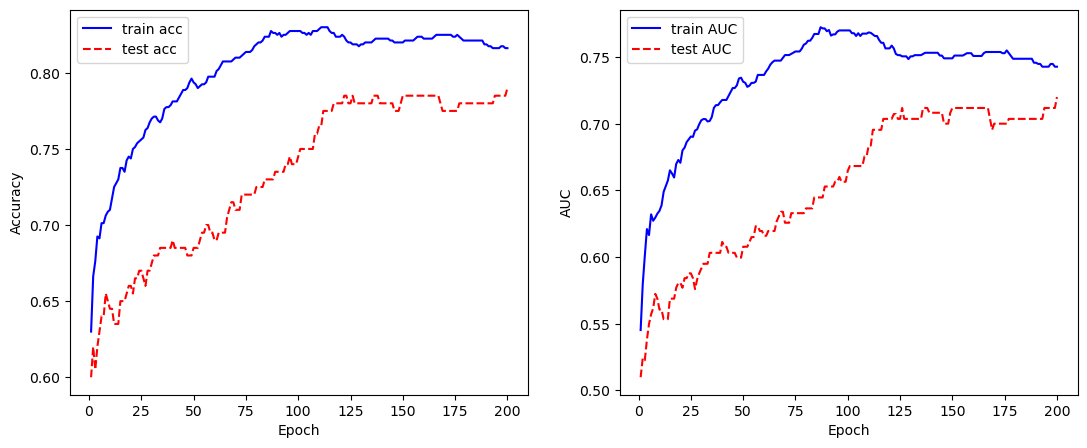
最后,我们把训练过程中在训练集和测试集上的精确率和 AUC 绘制出来,观察训练效果。
# 绘制训练曲线plt.figure(figsize=(13, 5))x_plot = np.arange(len(train_acc)) + 1plt.subplot(121)plt.plot(x_plot, train_acc, color='blue', label='train acc')plt.plot(x_plot, test_acc, color='red', ls='--', label='test acc')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.subplot(122)plt.plot(x_plot, train_auc, color='blue', label='train AUC')plt.plot(x_plot, test_auc, color='red', ls='--', label='test AUC')plt.xlabel('Epoch')plt.ylabel('AUC')plt.legend()plt.show()
7.6 本章小结
本章介绍了双线性模型的来源和特点,以及与线性模型的区别。双线性模型通过引入满足双线性性质的函数,相比于线性模型提升了对特征间关系建模的能力,从而达到更好的预测效果。本章以因子分解机和概率矩阵分解两个推荐系统中的常用模型为例,具体讲解了双线性模型的应用,并动手实现了两个模型。MF 模型和 FM 模型的应用场景不同。在 FM 中,用户的特征已知,我们希望挖掘特征与输出、特征与特征之间的关系;而在 MF 中,用户和物品的特征都是未知的,需要从模型训练得到。这两个模型都是目前推荐系统所用模型的基础,从它们改进和衍生的模型仍然有广泛应用。
习题
以下关于双线性模型的说法,不正确的是: A. 双线性模型考虑了特征之间的关联,比线性模型建模能力更强。 B. 在因子分解机中,因为引入了特征的乘积,只有特征
与 都不为零时才能更新参数 。 C. 可以通过重新设置参数,把因子分解机中的常数项和一次项都合并到二次项里,得到更一般的表达式。 D. 在矩阵分解中,最优的特征数量 是超参数,不能通过公式推导出来。 以下哪一个模型不是关于双线性模型: A.
。 B. 。 C. 。 D. 。 关于多域独热编码,思考其相比于如下编码方式的优势:针对每一个域,依次把其中的离散取值以自然数(以 0 开始)作为编码,在编码后每个域就对应一个自然数。例如图 7-3 中产地上海对应为 1,深圳对应为 3,生产月份 2 月对应为 1,12 月对应 11,食品种类乳制品对应为 0,图中的整个编码向量为
。 试修改 MF 的
pred(self, user_id, item_id)函数,在模型预测中加入全局打分偏置、用户打分偏置和物品打分偏置,类似 FM 模型中的常数项部分,观察模型拟合性能指标的变化。试基于本章的 MF 代码,调试不同的超参数,包括
和 ,关注训练集和测试集的性能指标的改变,根据训练和测试的性能曲线,判定哪些超参数导致过拟合。 试通过代码实验来验证双线性模型 FM 做回归或分类任务时,其优化目标相对参数是非凸的,也即是,设置不同的参数初始值,使用同样的 SGD 学习算法,最后参数会收敛到不同的位置。
拓展阅读:概率矩阵分解
概率矩阵分解(probabilistic matrix factorization,PMF)
其中
这里,我们用
对于那些空缺的
根据全概率公式
其中
再代入
计算得到
其中,
于是,最大化对数概率就等价于最小化损失函数
将损失函数对
令梯度为零,解得:
在正则化约束一节中我们讲过,根据矩阵相关的理论,只要
参考文献
[1] 矩阵分解模型论文:Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37.
[2] 因子分解机论文:Rendle S. Factorization machines[C]//2010 IEEE International conference on data mining. IEEE, 2010: 995-1000.
[3] 概率矩阵分解论文:Mnih A, Salakhutdinov R R. Probabilistic matrix factorization[J]. Advances in neural information processing systems, 2007, 20.