第 17 章 EM算法
本章我们继续介绍概率相关模型的算法。在前面的章节中,我们已经讲解了贝叶斯网络与最大似然估计(MLE)。对于监督学习的任务,设数据集的样本为
更进一步思考,真实世界的数据分布往往较为复杂,其背后往往具有一定的结构性,直接使用一个概率分布模型无法有效刻画数据分布。例如,我们可以假设数据服从高斯混合模型(Gaussian mixture model,GMM)
在GMM中,我们要求解的参数共有两种,一种是每个高斯分布的参数
从贝叶斯网络的角度来看,上面的分析过程建立了如下图所示的贝叶斯网络。其中,
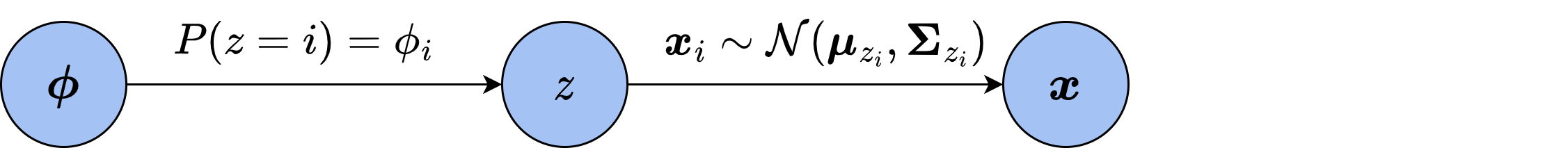
按照MLE的思想,参数的似然就是在此参数条件下出现观测到的数据分布的概率,也即
为了求出使对数似然最大化的参数,我们需要令对数似然对3个参数的梯度均为零:
然而,上述方程的求解非常复杂,并且没有解析解。因此,我们需要寻找其他方法求解。本章介绍的EM算法是一种求解复杂分布参数的通用算法。
17.1 高斯混合模型的EM算法
我们在最开始为了拆分
求这一函数的最大值就相对容易了。首先,由于
这里,
求和中每一项的因子
反过来考虑,如果我们已经知道了分布的参数
在各个参数已知的情况下,分子分母都可以直接计算出来。到此为止,看起来我们似乎在进行循环论证,在已知
期望步骤(E-step):固定各个参数,由数据集中的样本统计计算隐变量
的后验分布 。 最大化步骤(M-step):固定隐变量,最大化参数的对数似然
。
由于两步分别在计算样本的统计期望和最大化参数的对数似然,这样交替优化隐变量和参数的方法就称为期望-最大化算法,简称EM算法。
17.2 动手求解GMM拟合数据分布
虽然GMM是由高斯分布组成的,然而理论上它可以用来拟合任意的数据分布。如图17-2所示,左上角是由
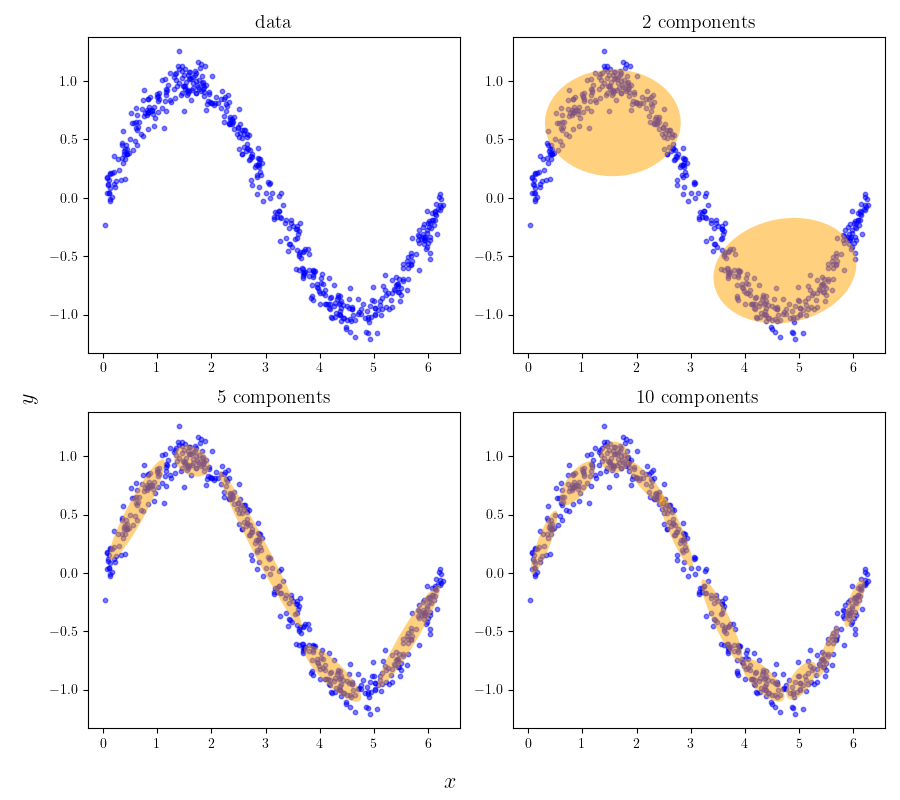
从上图的拟合结果中我们还可以发现,如果我们有一组分布未知的数据,并且还希望能按照同样的分布生成一些新的数据,那么也可以先用GMM对数据进行拟合,再由它来继续做数据生成。因此,从数据中拟合GMM就变得十分重要。下面,我们就来用上文介绍的EM算法来求解GMM模型。简单起见,我们就采用与上图中相同的正弦数据集。
import numpy as npimport matplotlib.pyplot as pltX = np.loadtxt('sindata.csv', delimiter=',')
在实现EM算法之前,我们先来定义计算高斯分布概率密度
式中,numpy.linalg中的工具直接计算得到。此外,我们通常会计算概率密度的对数而非概率密度本身,这是因为形如
# 计算多元高斯分布的概率密度的对数def log_gaussian_prob(x, mu, sigma):d = x.shape[-1]det = np.linalg.det(sigma)diff = x - mu# 由于x可能包含多个样本# x.T @ inv(sigma) @ x 的第二个乘法只需要保留前后样本一致的部分,# 所以第二个乘法用点乘再求和代替# 此外,由于数据存储维度的问题,这里的转置和上面公式中的转置相反log_prob = -d / 2 * np.log(2 * np.pi) - 0.5 * np.log(det) \- 0.5 * np.sum(diff @ np.linalg.inv(sigma) * diff, axis=-1)return log_prob
接下来是EM算法的核心部分。为了使算法的调用和参数设置尽可能灵活,我们把EM算法封装在GMM类中。上文中只介绍了EM算法的迭代过程,但没有提及该如何初始化算法的各个参数。为了使算法从比较良好的初始状态出发,我们可以用k-means算法先对数据做聚类,得到每个点的聚类标签。如果将每个聚类看成一个高斯分布,那么这就相当于计算出了每个样本属于哪个分布,也就是隐变量
下面的代码中,我们分别实现随机初始化和k-means初始化两种方法。需要注意,协方差矩阵必须是半正定的,因此我们先在
from sklearn.cluster import KMeansfrom scipy.special import logsumexpclass GMM:def __init__(self, n_components=2, eps=1e-4, max_iter=100, init='random'):# n_components:GMM中高斯分布的数目# eps:迭代精度,当对数似然的变化小于eps时迭代终止# max_iter:最大迭代次数# init:初始化方法,random或kmeansself.k = n_componentsself.eps = epsself.max_iter = max_iterself.init = initself.phi = None # 隐变量的先验分布,即每个高斯分布的占比self.means = None # 每个高斯分布的均值self.covs = None # 每个高斯分布的协方差def EM_fit(self, X):# 用EM算法求解GMM的参数# 参数初始化if self.init == 'random':self._random_init_params(X)elif self.init == 'kmeans':self._kmeans_init_params(X)else:raise NotImplementedErrorll = self._calc_log_likelihood(X) # 当前的对数似然n, d = X.shape# 开始迭代qz = np.zeros((n, self.k)) # z的后验分布for t in range(self.max_iter):# E步骤,更新后验分布for i in range(self.k):# 计算样本属于第i类的概率log_prob = log_gaussian_prob(X, self.means[i], self.covs[i])qz[:, i] = self.phi[i] * np.exp(log_prob)# 归一化qz = qz / np.sum(qz, axis=1).reshape(-1, 1)# M步骤,统计更新参数,最大化对数似然self.phi = np.sum(qz, axis=0) / n # 更新隐变量分布for i in range(self.k):# 更新均值self.means[i] = np.sum(qz[:, i, None] * X, axis=0) \/ n / self.phi[i]# 更新协方差diff = X - self.means[i]self.covs[i] = (qz[:, i, None] * diff).T @ diff \/ (n - 1) / self.phi[i]# 判断对数似然是否收敛new_ll = self._calc_log_likelihood(X)# assert new_ll >= ll, new_llif new_ll - ll <= self.eps:breakll = new_lldef _calc_log_likelihood(self, X):# 计算当前的对数似然ll = 0for i in range(self.k):log_prob = log_gaussian_prob(X, self.means[i], self.covs[i])# 用logsumexp简化计算# 该函数底层对对数-求和-指数形式的运算做了优化ll += logsumexp(log_prob + np.log(self.phi[i]))return lldef _random_init_params(self, X):self.phi = np.random.uniform(0, 1, self.k) # 随机采样phiself.phi /= np.sum(self.phi)self.means = np.random.uniform(np.min(X), np.max(X),(self.k, X.shape[1])) # 随机采样均值self.covs = np.random.uniform(-1, 1,(self.k, X.shape[1], X.shape[1])) # 随机采样协方差self.covs += np.eye(X.shape[1]) * X.shape[1] # 加上维度倍的单位矩阵def _kmeans_init_params(self, X):# 用Kmeans算法初始化参数# 简单起见,我们直接调用sklearn库中的Kmeans方法kmeans = KMeans(n_clusters=self.k, init='random',random_state=0).fit(X)# 计算高斯分布占比data_in_cls = np.bincount(kmeans.labels_, minlength=self.k)self.phi = data_in_cls / len(X)# 计算均值和协方差self.means = np.zeros((self.k, X.shape[1]))self.covs = np.zeros((self.k, X.shape[1], X.shape[1]))for i in range(self.k):# 取出属于第i类的样本X_i = X[kmeans.labels_ == i]self.means[i] = np.mean(X_i, axis=0)diff = X_i - self.means[i]self.covs[i] = diff.T @ diff / (len(X_i) - 1)
最后,我们设置好超参数,用GMM模型拟合正弦数据集,并绘图观察拟合效果。由于绘图过程要用到从协方差矩阵计算椭圆参数、用matplotlib中的工具绘制椭圆等方法,较为复杂,我们在这里直接给出绘制椭圆的函数和使用方法,不再具体讲解绘制过程。我们分别用2、3、5、10个高斯分布和两种初始化方法进行拟合,并把结果画在一起进行对比。
import matplotlib as mpldef plot_elipses(gmm, ax):# 绘制椭圆# gmm:GMM模型# ax:matplotlib的画布covs = gmm.covsfor i in range(len(covs)):# 计算椭圆参数cov = covs[i][:2, :2]v, w = np.linalg.eigh(cov)u = w[0] / np.linalg.norm(w[0])ang = np.arctan2(u[1], u[0])ang = ang * 180 / np.piv = 2.0 * np.sqrt(2.0) * np.sqrt(v)# 设置椭圆的绘制参数# facecolor和edgecolor分别是填充颜色和边缘颜色# 可以自由调整elp = mpl.patches.Ellipse(gmm.means[i, :2], v[0], v[1],180 + ang, facecolor='orange', edgecolor='none')elp.set_clip_box(ax.bbox)# 设置透明度elp.set_alpha(0.5)ax.add_artist(elp)
# 超参数max_iter = 100eps = 1e-4np.random.seed(0)n_components = [2, 3, 5, 10]inits = ['random', 'kmeans']fig = plt.figure(figsize=(13, 25))for i in range(8):ax = fig.add_subplot(4, 2, i + 1)# 绘制原本的数据点ax.scatter(X[:, 0], X[:, 1], color='blue', s=10, alpha=0.5)# 初始化并拟合GMMk = n_components[i // 2]init = inits[i % 2]gmm = GMM(k, eps, max_iter, init)gmm.EM_fit(X)# 绘制椭圆plot_elipses(gmm, ax)ax.set_title(f'{k} components, {init} init')plt.show()
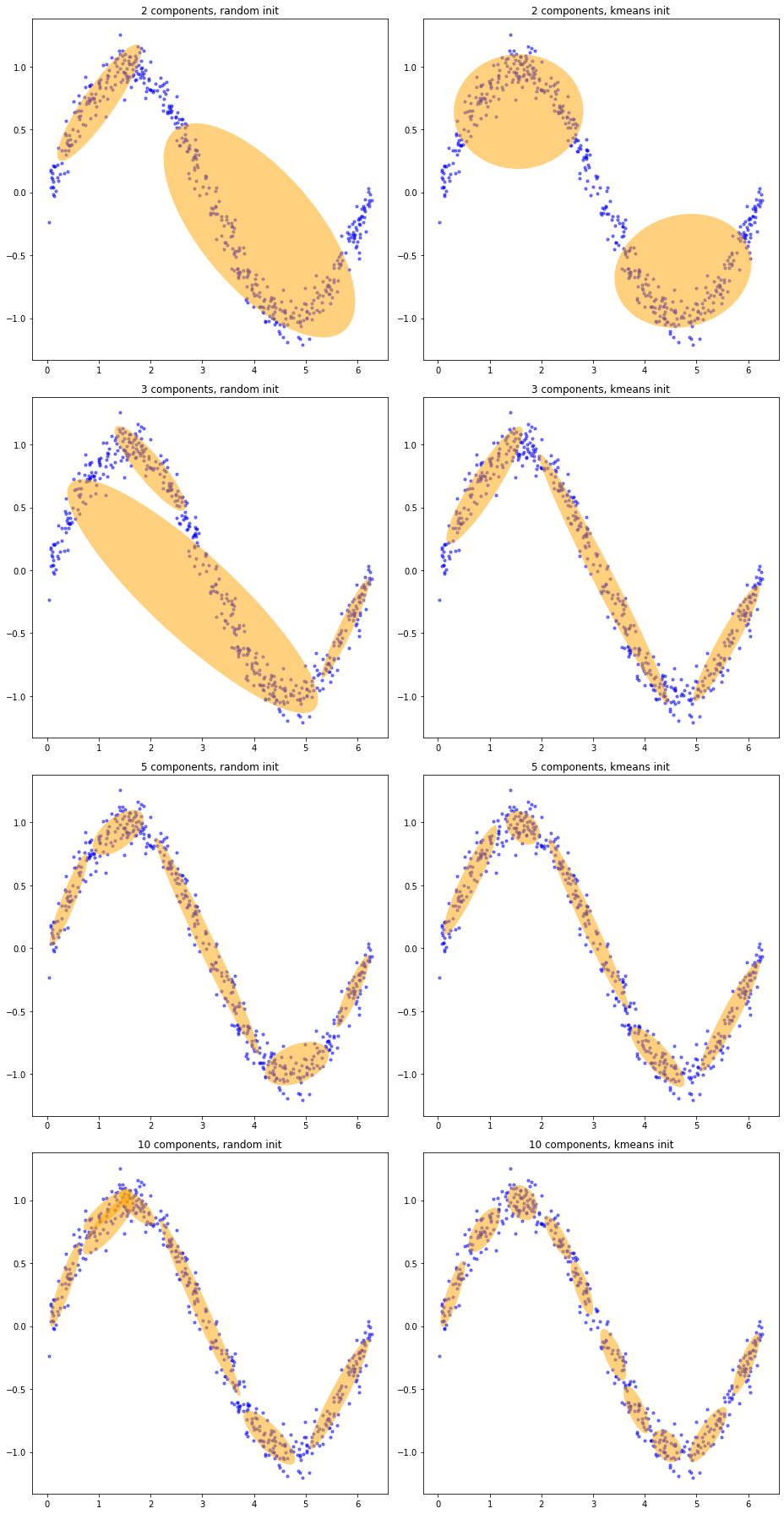
从结果图中可以看出,用k-means初始化参数可以让初始的聚类中心比较接近最优的高斯分布均值,而随机初始化的参数则很容易陷入局部的驻点。虽然EM算法理论上是收敛的,但是它并不保证收敛到最优解。并且,如果我们设置了对数似然的变化精度为算法的终止条件,那么算法同样可能在变化较为缓慢的驻点出停止,得到较差的解。因此,EM算法的参数初始化同样重要。除了k-means之外,我们还可以用随机性更小、效果更好的k-means++算法进行初始化,这部分代码留作习题,请读者自行完成。
小故事: GMM通常用来拟合数据分布后,再生成相同分布的数据。像这样从数据中学习出分布、再从分布出发完成后续任务的模型称为生成模型(generative model)。与之相对,直接学习样本特征和样本标签直接关联的模型称为判别模型(discriminative model)。我们之前介绍的线性回归等有监督学习模型都属于判别模型。从概率分布的角度出发,假设训练样本为
,判别模型会将 与 关联起来,直接学习由样本 给出标签 的条件概率分布 ;而生成模型将所有样本关联起来,学习了联合分布 ,然后由此构建对其中标签的条件概率分布 。在无监督学习下,生成模型只需要学习 即可。 现代深度学习中,生成模型同样有广泛的应用。2013年,迪德里克·金玛(Diederik Kingma)和 马克斯·韦林(Max Welling)提出了变分自编码器;2014年,伊恩·古德费洛(Ian Goodfellow)提出了划时代的生成对抗网络。这两类模型衍生出了许多算法,让生成模型在深度学习时代保有了自己的一席之地。如今,最新的扩散模型在图像任务上取得了令人震惊的效果,并催生了足以以假乱真的人工智能绘画。用于文本任务的生成式预训练变换器可以生成高质量的自然语言,以它为基础的ChatGPT掀起了新一轮人工智能热潮。
17.3 一般情况下的EM算法
对于更一般的、样本分布不服从GMM的情况,我们同样可以模仿上面的步骤使用EM算法推进学习。设样本为
上式的第二个求和是对隐变量
其中,
然而到此为止,我们并没有论证为什么EM算法是合理的。为什么可以假设隐变量已知?这样的迭代方式为何能给出收敛的结果?为了探究这一问题,我们来从头考虑MLE的求解。我们不妨先对原本的
为了进行放缩,我们介绍一个重要的常用不等式:琴生不等式(Jensen's inequality)。设函数
下图以
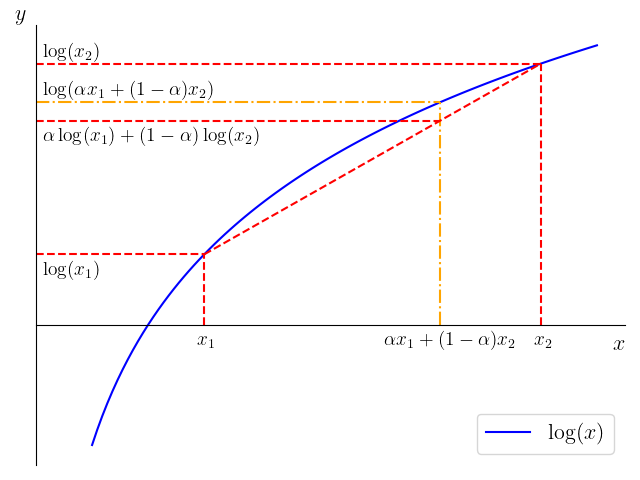
琴生不等式还可以推广到多个点的情况。设
注意到在上面对数似然的表达式中,
上式给出了对数似然的下界。虽然最大化
其中
恰好是隐变量
17.4 EM算法的收敛性
上一节中,我们通过放缩解释了EM算法的含义以及合理性,本节来继续证明算法的收敛性。由于我们最终要求解的是参数
证明的关键在于,注意到
上式的第一个不等号是琴生不等式,且在参数为
如果记
那么,EM算法的E步骤就在固定
17.5 本章小结
本章介绍了求解带有隐变量数据分布下的MLE问题的EM算法。本质上,EM算法将MLE问题分解成两步,E步骤通过推导隐变量的后验分布来求出对数似然的良好下界,M步骤中则更新模型参数来优化该下界。我们还证明了,如此迭代下去,EM算法必定会收敛。事实上,我们介绍过的k均值聚类算法也属于EM算法的一种,只不过它优化的目标与对数似然有一些区别,但迭代的方式和基本思想是一致的。在实践中,EM算法常被用来求解GMM的参数。由于GMM可以拟合任意形式的数据分布,并且高斯分布计算简单、性质良好,EM算法也就显得非常重要了。EM算法与决策树、支持向量机等算法同样,也在2008年被评为“数据挖掘十大算法”之一。
习题
琴生不等式:设
为凸函数, 为随机变量,那么 ,是否正确? A. 正确 B. 错误 EM算法中,E步骤是在构造对数似然的一个(良好)下界,然后M步骤是在优化此下界。这个说法是否正确? A. 正确 B. 错误
以下关于混合高斯模型的说法不正确的是: A. GMM可以拟合任意分布,在现实生活中也有很多真实案例。 B. 因为高斯分布在全空间中的概率密度都不为零,所以一个样本可以同时属于 GMM 中的多个高斯分布。 C. GMM中每个高斯分布的权重取决于该分布对应数据的数量。 D. 高斯模型是对数据分布的先验假设,因此GMM是参数化模型。
以下关于EM算法的说法不正确的是: A. EM算法是一类优化算法的统称,不只可以用来求解GMM的参数。 B. 优化目标函数的性质对EM算法的收敛性没有影响。 C. 在每个EM步骤后,当前参数计算出的似然不可能降低。 D. EM算法的本质是坐标上升,求解SVM所用的SMO也属于这一类算法。
在17.2节的代码中,将k均值算法改为k-means++算法,观察拟合效果的变化。
试使用本章代码的
_calc_log_likelihood函数,观察EM算法每一轮迭代的对数似然值的变化,验证EM算法关于对数似然的单增优化性质和收敛性。