第 18 章 自动编码器
在前面的章节中,我们介绍了各种类型的无监督学习算法,如聚类算法、降维算法等。归根结底,无监督学习的目的是从复杂数据中提取出可以代表数据的特征,例如数据的分布、数据的主要成分等等,再用这些信息帮助后续的其他任务。随着机器学习向深度学习发展和神经网络的广泛应用,用神经网络提取数据特征的方法也越来越重要。本章介绍的自动编码器(autoencoder,AE)就是其中最基础的一种无监督特征提取方法。
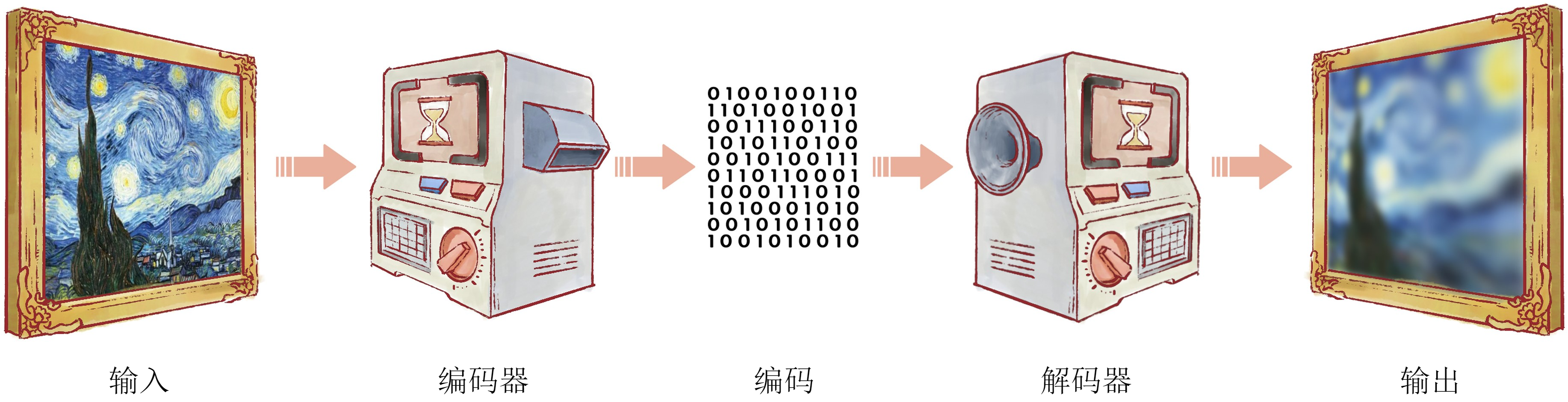
自动编码器的原理并不复杂,它将一个输入数据样本压缩成一个低维特征向量表示,然后试图基于该低维特征向量恢复出原数据样本。可以想象,如果该低维特征向量能充分保留原数据样本的信息,那么就可能基于该低维特征向量较好地恢复出原数据。比如在图18-1中,我们希望把梵高的《星空》存储在一台机器中,但是这幅画的细节非常丰富,如果用非常高的精度存储,要占用很大的空间。因此,我们可以通过某种算法,把这幅画编码成较少的数据;需要读取时,再通过对应的算法解码出来。这样,虽然解码出的画丢失了一些细节,但是存储的开销也大大降低了。计算机中常见的图像格式JPEG就是一种有损的图像编码方法。自动编码器也一样,当我们提取特征时,必然也会保留主要特征、丢弃次要特征,因此最后解码的结果通常不会和输入完全相同。
设数据集
编码器和解码器的设计方式有很多。如果我们对数据分布有足够的先验知识,当然可以直接通过这些知识来对数据做编码和解码。例如,如果所有的样本都是独热向量,我们就可以用
18.1 自动编码器的结构
设编码器表示的映射为
其中
这时,我们可以来考虑编码器的任务目标。编码器需要将高维的样本变换为低维的特征,并且这些特征应当保留原始样本尽可能多的信息。从高维到低维的变换中必定伴随着不可逆的信息损失,如果特征质量较差,保留的信息较少,那么我们无论如何都不可能从特征恢复出原始样本。反过来说,我们可以引入第二个网络
其中
该损失又称为重建损失(reconstruction loss)。由于
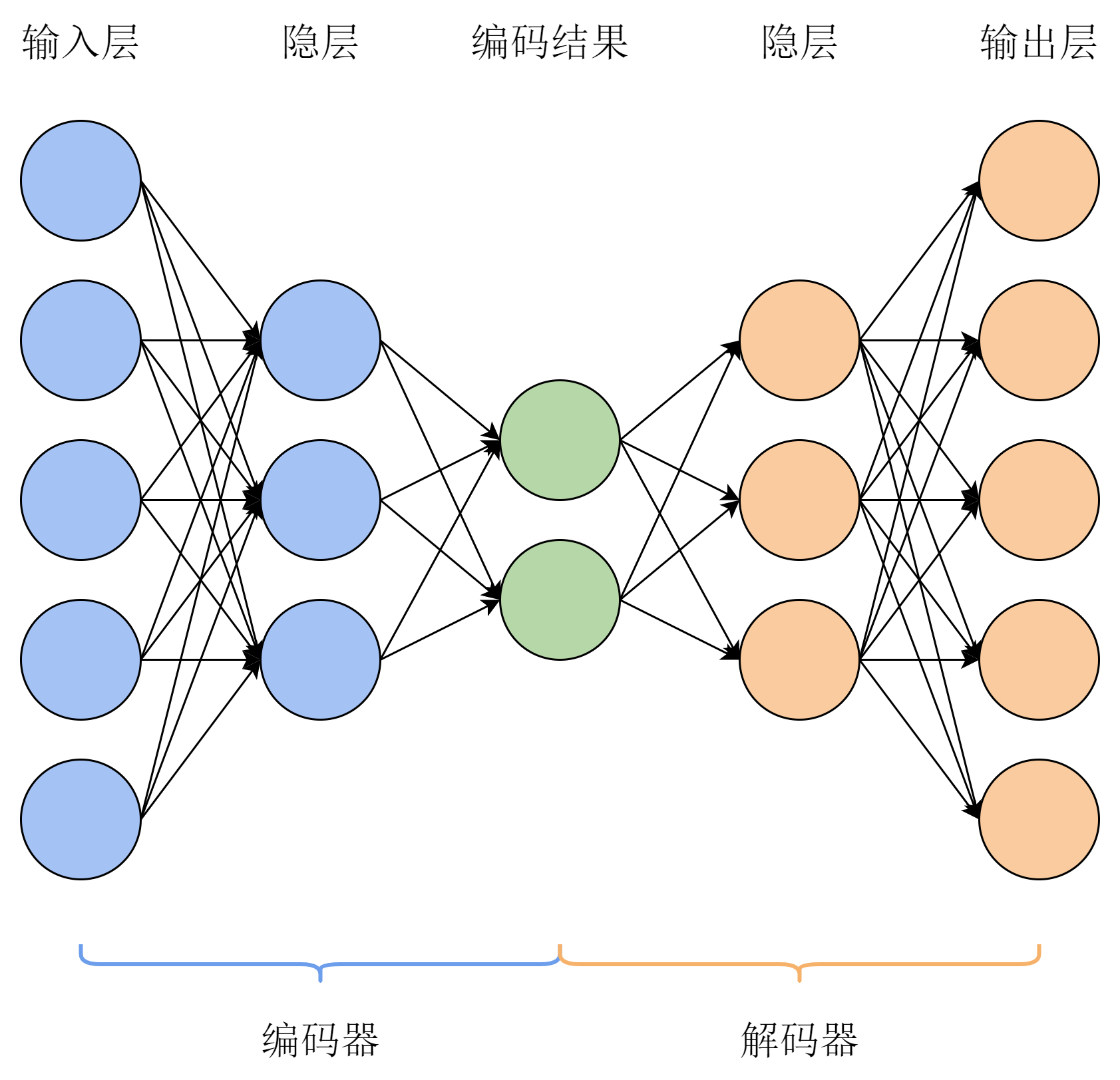
将上面的编码器和解码器组合起来,就得到了自动编码器,其结构如图18-2所示。通常来说,自动编码器的结构不会特别复杂,简单的MLP就足够满足任务的要求。考虑到编码与解码过程的对称性,设编码器的隐藏层大小依次为
下面,我们在手写数字数据集MNIST上实现自动编码器,用自动编码器提取图像的特征,并观察用解码器还原后的效果。
18.2 动手实现自动编码器
在K近邻算法一章中,我们已经介绍过MNIST数据集的内容。该数据集包含一些手写数字的黑白图像,其中白色的部分是数字,黑色的部分是背景,所有图像的大小都是28
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport torchimport torch.nn as nn# 导入数据mnist_train = pd.read_csv("mnist_train.csv")mnist_test = pd.read_csv("mnist_test.csv")# 提取出图像信息,并将内容从0~255的整数转换为0.0~1.0的浮点数# 图像大小为28*28,数组中每一行代表一张图像x_train = mnist_train.iloc[:, 1:].to_numpy().reshape(-1, 28 * 28) / 255x_test = mnist_test.iloc[:, 1:].to_numpy().reshape(-1, 28 * 28) / 255print(f'训练集大小:{len(x_train)}')print(f'测试集大小:{len(x_test)}')
训练集大小:60000测试集大小:10000
我们先来展示部分数据集中的图像,来对数据集有更清晰的认识。考虑到后面还要比较重建图像和原始图像,我们把展示图像的方法写成函数。
def display(data, m, n):# data:图像的像素数据,每行代表一张图像# m,n:按m行n列的方式展示前m * n张图像img = np.zeros((28 * m, 28 * n))for i in range(m):for j in range(n):# 填充第i行j列图像的数据img[i * 28: (i + 1) * 28, j * 28: (j + 1) * 28] = \data[i * m + j].reshape(28, 28)plt.figure(figsize=(m * 1.5, n * 1.5))plt.imshow(img, cmap='gray')plt.show()display(x_test, 3, 5)

接下来,我们来用PyTorch库实现自动编码器的网络结构。这里,我们用两层隐层的MLP作为编码器和解码器,且全部使用逻辑斯谛激活函数。由于两者结构本质上相同,我们只实现一个MLP类,再分别实例化为编码器和解码器。原始图像拉平成一维后大小是
# 多层感知机class MLP(nn.Module):def __init__(self, layer_sizes):super().__init__()self.layers = nn.ModuleList() # ModuleList用列表存储PyTorch模块num_in = layer_sizes[0]for num_out in layer_sizes[1:]:# 创建全连接层self.layers.append(nn.Linear(num_in, num_out))# 创建逻辑斯谛激活函数层self.layers.append(nn.Sigmoid())num_in = num_outdef forward(self, x):# 前向传播for l in self.layers:x = l(x)return xlayer_sizes = [784, 256, 128, 100]encoder = MLP(layer_sizes)decoder = MLP(layer_sizes[::-1]) # 解码器的各层大小与编码器相反
我们按照上面讲解的方式,先用编码器计算出每个样本的编码
# 训练超参数learning_rate = 0.01 # 学习率max_epoch = 10 # 训练轮数batch_size = 256 # 批量大小display_step = 2 # 展示间隔np.random.seed(0)torch.manual_seed(0)# 采用Adam优化器,编码器和解码器的参数共同优化optimizer = torch.optim.Adam(list(encoder.parameters()) \+ list(decoder.parameters()), lr=learning_rate)# 开始训练for i in range(max_epoch):# 打乱训练样本idx = np.arange(len(x_train))idx = np.random.permutation(idx)x_train = x_train[idx]st = 0ave_loss = [] # 记录每一轮的平均损失while st < len(x_train):# 遍历数据集ed = min(st + batch_size, len(x_train))X = torch.from_numpy(x_train[st: ed]).to(torch.float32)Z = encoder(X)X_rec = decoder(Z)loss = 0.5 * nn.functional.mse_loss(X, X_rec) # 重建损失ave_loss.append(loss.item())optimizer.zero_grad()loss.backward() # 梯度反向传播optimizer.step()st = edave_loss = np.average(ave_loss)if i % display_step == 0 or i == max_epoch - 1:print(f'训练轮数:{i},平均损失:{ave_loss:.4f}')# 选取测试集中的部分图像重建并展示with torch.inference_mode():X_test = torch.from_numpy(x_test[:3 * 5]).to(torch.float32)X_test_rec = decoder(encoder(X_test))X_test_rec = X_test_rec.cpu().numpy()display(X_test_rec, 3, 5)
训练轮数:0,平均损失:0.0307

训练轮数:2,平均损失:0.0166

训练轮数:4,平均损失:0.0126

训练轮数:6,平均损失:0.0106

训练轮数:8,平均损失:0.0096

训练轮数:9,平均损失:0.0089

最后,我们把得到的模型在测试集上选取部分图像进行重建,并与原图比较,观察模型的效果。可以看出,重建的图像与原始图像非常相近,肉眼很容易辨认出重建图像中的数字,但也能观察出部分缺失的细节。然而,原始图像的大小是784像素,而经由编码器得到的编码长度只有100,大大减小了数据的复杂度。即使算上解码器的模型参数,因为解码器对所有图像的编码都是通用的,无非是加上一个常数。但是需要存储的图像越多,由编码节约的空间就越大,完全可以覆盖模型参数需要的空间了。
print('原始图像')display(x_test, 3, 5)print('重建图像')X_test = torch.from_numpy(x_test[:3 * 5]).to(torch.float32)X_test_rec = decoder(encoder(X_test))X_test_rec = X_test_rec.detach().cpu().numpy()display(X_test_rec, 3, 5)
原始图片

重建图片

18.3 本章小结
本章介绍了无监督学习和深度学习中的重要模型之一——自动编码器。它结构简单,不依赖监督信号,只需要数据本身,易于和其他模块结合,可以作为复杂任务的数据处理和特征提取步骤。例如我们要完成手写数字分类任务,就可以先用自动编码器获得样本的特征,再用这些特征作为输入,训练其他有监督学习任务的机器学习模型。自动编码器的这种自监督学习范式是现代深度学习中的一种非常重要的范式,也是机器学习里重要的思维方式之一。
除了上面讲解的最简单的自动编码器之外,它还有许多变式。栈式自动编码器(stacked autoencoder)
习题
以下关于自动编码器的说法不正确的是: A. 自动编码器是一种特征提取技术,还可以用来去噪。 B. 自动编码器的训练方式属于无监督学习。 C. 自动编码器得到的编码完整保留了原始输入的信息,从而可以再用解码器还原。 D. 自动编码器的编码部分和解码部分是一体的,无法分开训练。
自动编码器作为特征提取结构,可以和其他算法组合。将本章的自动编码器提取出的特征输入到MLP里,利用MLP完成有监督的手写数字分类任务。
自动编码器的基础结构并不一定局限于MLP,对于图像任务来说,CNN在理论上更加合适。尝试用CNN搭建自动编码器,该模型的解码部分同样与编码部分结构相同、顺序相反,并且将编码时的池化用上采样代替。
降噪编码器是自动编码器的一个变种,它主动为输入样本添加噪声,将带噪的样本给自动编码器训练,与原始样本计算重建损失。这样训练出的自动编码器就有了去噪功能。试给手写数字图像加上噪声,用降噪编码器为其去噪,观察去噪后的图像与原始图像的区别。
参考文献
[1] 栈式自动编码器论文:Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks[J]. Advances in neural information processing systems, 2006, 19.
[2] 降噪自动编码器论文:Vincent P, Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders[C]//Proceedings of the 25th international conference on Machine learning. 2008: 1096-1103.
[3] 变分自动编码器论文:Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013.