第 8 章 神经网络与多层感知机
本章将会介绍机器学习中最重要的内容之一——神经网络(neural network,NN),它是深度学习的基础。神经网络的名称来源于生物中的神经元。自有计算机以来,人们就希望能让计算机具有和人类一样的智能,因此,许多研究者将目光放到了人类的大脑结构上。作为生物神经系统的基本单元,神经元在形成智能的过程中起到了关键作用。神经元的结构并不复杂,简单来说,神经元由树突、轴突和细胞体构成。图 8-1 是神经元的结构示意图。由其他神经元传来的神经脉冲在细胞间通过神经递质传输。神经递质被树突接收后,相应的神经信号传给细胞体,由细胞体进行处理并积累。当积累神经递质的兴奋性超过了某个阈值,就会触发一个动作电位,将新的信号传至轴突末梢的突触,释放神经递质给下一个神经元。生物的智能、运动等几乎所有生命活动的控制信号都由这些看似简单的神经元进行传输。
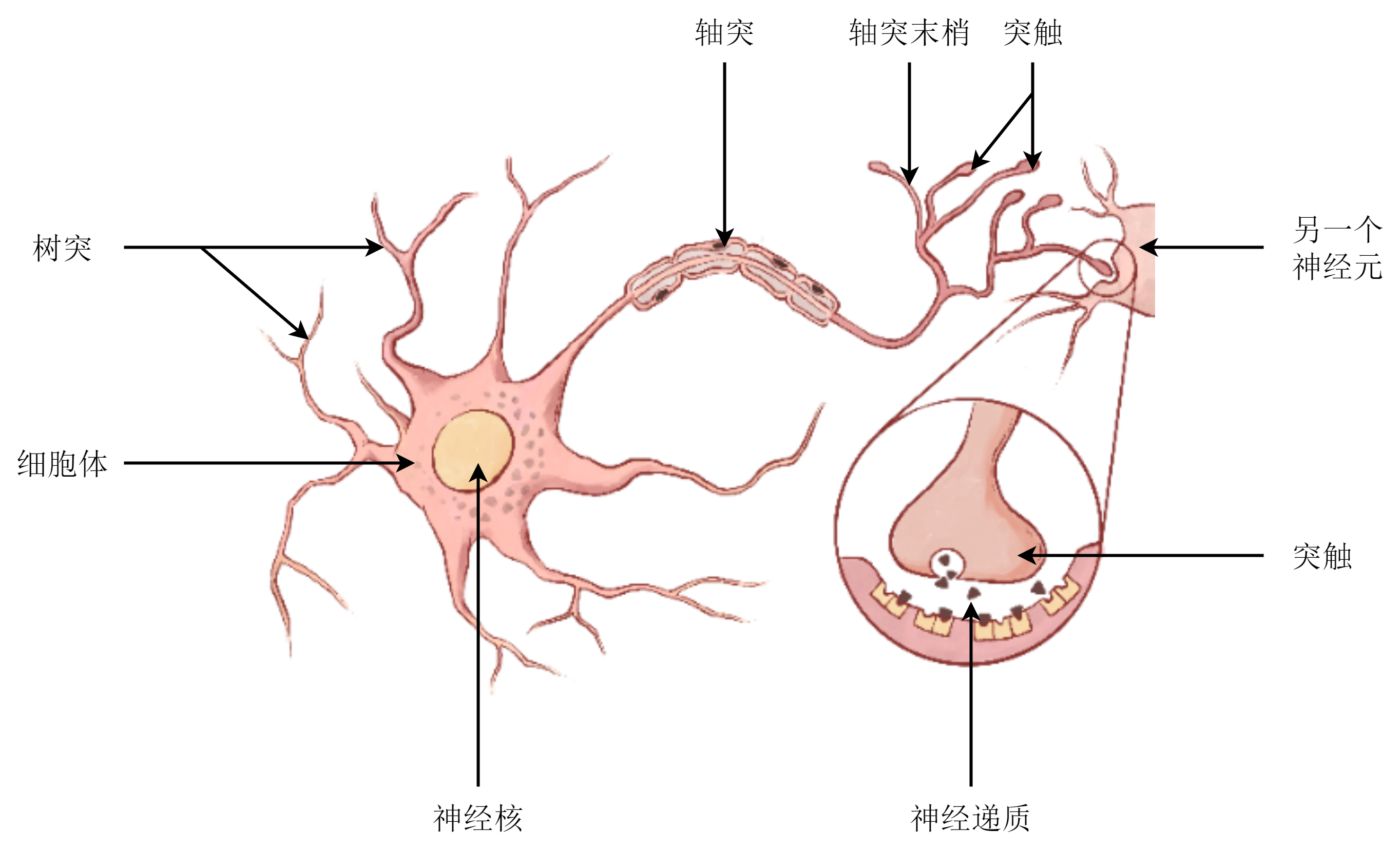
8.1 人工神经网络
既然动物能够通过神经元建立智能,我们自然会想,能不能通过模拟神经元的结构和行为方式,建立起人工智能呢?于是,从 1943 年的沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)开始,研究者们设计了人工神经网络(artificial neural network,ANN),现在通常简称为神经网络(NN)。在 NN 中,最基本的单位也是神经元。在最开始的设计中,人工神经元完全仿照生物神经元的结构和行为方式,而大量的神经元互相连接,构成一张有向图。每个神经元是一个节点,神经元之间的连接就作为有向边。设神经元
此外,每个神经元
8.2 感知机
上文提到的神经网络的最大问题在于,每条边上的权重都需要人为指定。当神经网络的规模较大、结构较为复杂时,我们很难先验地通过数学方法计算出合适的权重,从而这样的网络也很难用来解决实际问题。为了简化复杂的神经网络,1958 年,弗兰克·罗森布拉特(Frank Rosenblatt)提出了感知机(perceptron)的概念。他从生物接受刺激、产生感知的过程出发,用神经网络抽象出了这一模型,如图 8-2 所示。与原始的神经网络类似,输入经过神经元后被乘上权重并求和。但是,感知机还额外引入了偏置(bias)

感知机中有两个新引入的结构。第一是偏置,它相当于给线性变换加入了常数项。我们知道,对于一维的线性函数
感知机最重要的进步在于,它的参数可以自动调整,无须再由人工繁琐地一个一个调试。假设二分类问题中,样本的特征为
罗森布拉特利用生物中的负反馈调节机制来调整感知机的参数。对于该样本,感知机收到的反馈为
其中,
然而,感知机模型存在致命的缺陷,那就是它只能处理线性问题。1969 年,马文·明斯基(Marvin Minsky)提出了异或问题。对输入
表 8-1 异或运算的真值表
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
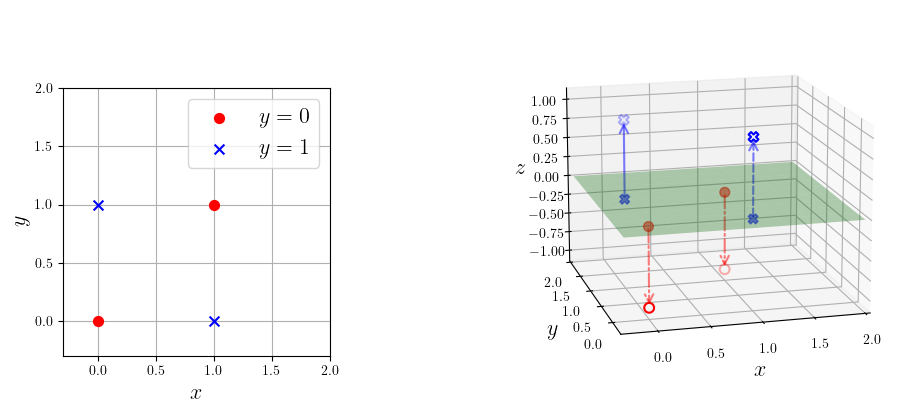
异或问题的输入只有 4 种可能,如果把所有输入和其输出在平面直角坐标系中画出来,无非是 4 个点而已,如图 8-3 所示。其中,左下和右上的点是红色,左上和右下的点是蓝色。要解决异或问题,模型只需要将红色和蓝色的点区分开。然而,读者可以自行验证,红点和蓝点无法只通过一条直线分隔开,从而感知机无法解决异或问题。这一事实被提出后,感知机的表达能力和应用场景遭到广泛质疑,神经网络的研究也陷入了寒冬。

8.3 隐含层与多层感知机
为了进一步增强网络的表达能力,突破只能解决线性问题的困境,有研究者提出增加网络的层数,即将一个感知机的输出作为输入,连接到下一个感知机上。如果一个感知机对应平面上的一条直线,那么多个感知机就可以将平面分隔成多边形区域,达到超越线性的效果。图 8-4 给出了一个形象的示例。

然而,如果不同层之间的神经元可以随意连接,往往会有多种结构可以解决同一个问题,从而大大增加结构设计的难度。例如,图 8-5 中的两种结构都可以解决异或问题,其中边上的数字代表权重
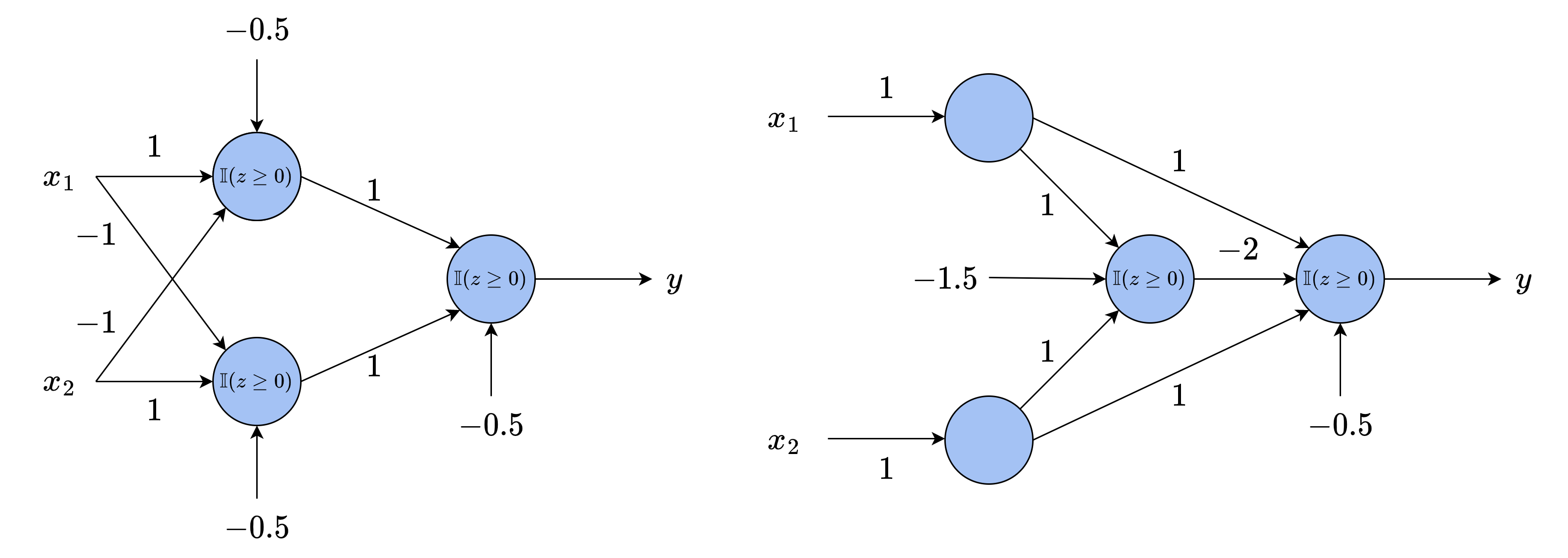
因此,当我们组合多个单层的感知机时,通常采用前馈(feedforward)结构,即将神经元分为不同的层,每一层只和其前后相邻层的神经元连接,层内以及间隔一层以上的神经元之间没有连接。这样,我们可以将网络的结构分为直接接收输入的输入层(input layer)、中间进行处理的隐含层(hidden layer)、以及最终给出结果的输出层(output layer)。图 8-6 是一个两层的前馈网络示意图。需要注意,前馈网络的层数是指权重的层数,即边的层数,而神经元上不携带权重。
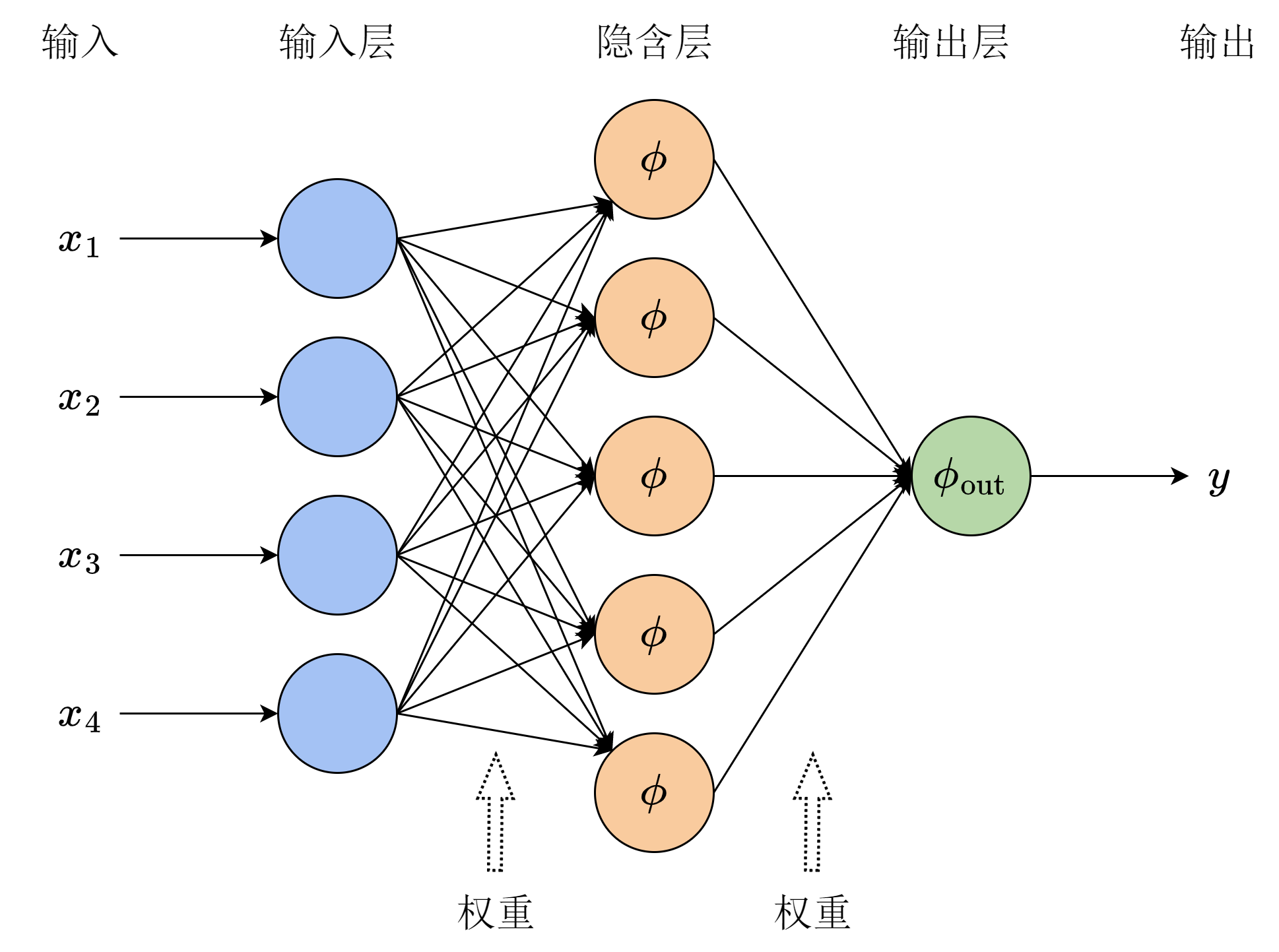
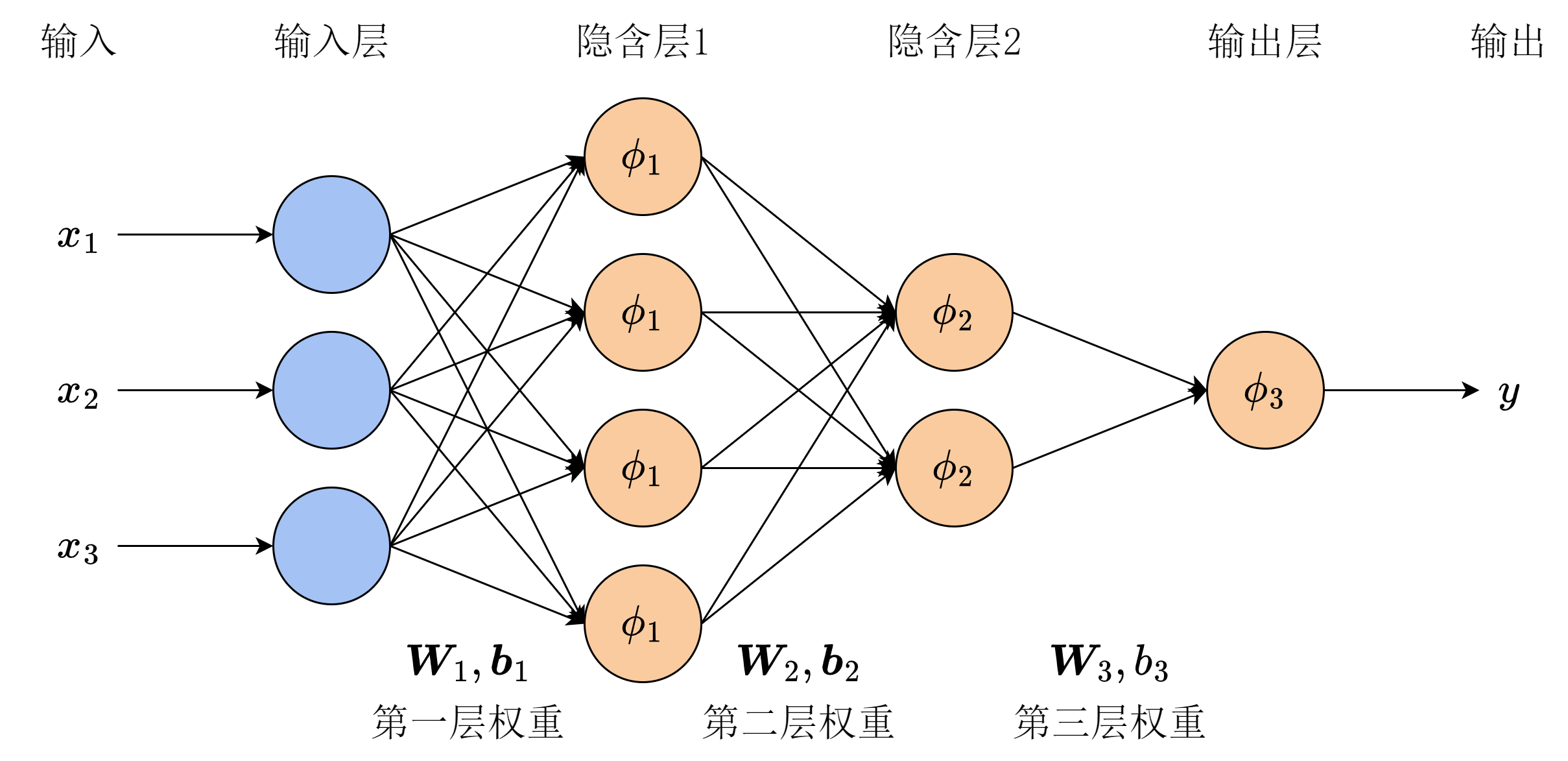
将多个单层感知机按前馈结构组合起来,就形成了多层感知机(multi-layer perceptron,MLP)。事实上,图 8-6 已经是一个两层的多层感知机,隐含层神经元内部的
下面,我们以图 8-7 中的三层 MLP 为例,详细写出 MLP 中由输入计算得到输出的过程。设第
第一层:
。由于下一层的维度是 4,因此 , ,输出 。 第二层:
。同理, , ,输出 。 第三层,即输出层:
。由于输出 是标量,这里 , 。
如果把上面三层所做的运算连起来写,就得到:
那么这些激活函数能否就用线性函数来实现,还是说一定得是非线性函数呢?我们可以做以下简单推导:假如所有的激活函数
这与一个权重
逻辑斯谛函数:
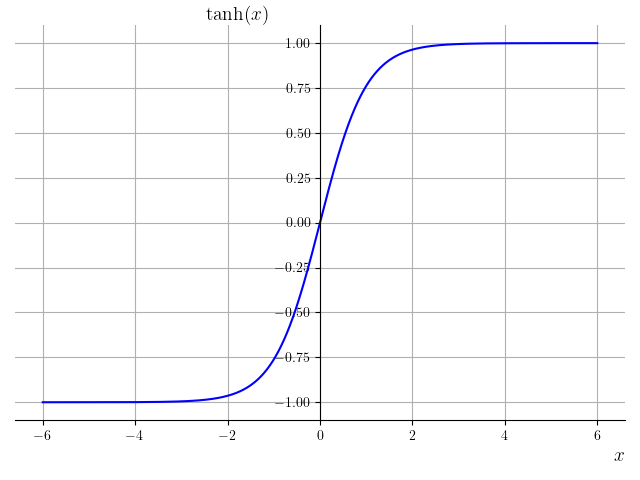
。该函数又称 sigmoid 函数,在逻辑斯谛回归一章中已经介绍过,会将 映射到 区间内。直观上,可以将 0 对应生物神经元的静息状态,1 对应兴奋状态。相比于示性函数 ,逻辑斯谛函数更加平滑,并且易于求导。逻辑斯谛函数的推广形式是 softmax 函数,两者没有本质不同。 双曲正切(tanh)函数:
。该函数将 映射到 ,图像如图 8-8 所示,与逻辑斯谛函数均为“S”形曲线,同样常用与分类任务。
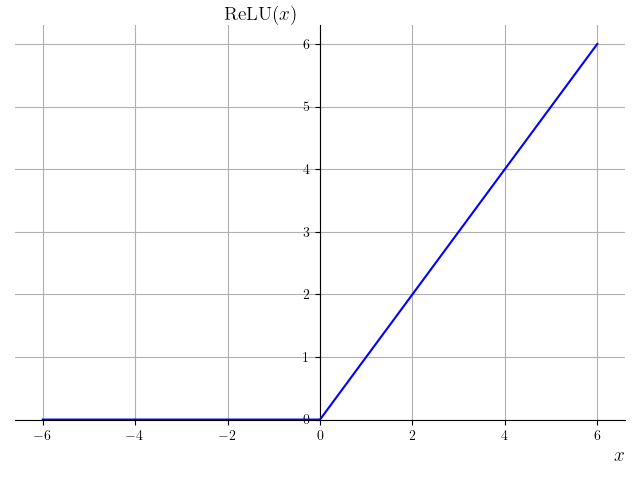
- 线性整流单元(rectified linear unit,ReLU):
。该函数将小于 0 的输入都变成 0,而大于 0 的输入保持原样,图像如图 8-9 所示。虽然函数的两部分都是线性的,但在大于 0 的部分并不像示性函数 一样是常数,因此存在梯度,并且保持了原始的输入信息。一些研究表明,ReLU 函数将大约一半的神经元输出设置为 0、即静息状态的做法,与生物神经元有相似之处。
在实践中,考虑到不同隐含层之间的对称性,我们一般让所有隐含层的激活函数相同。而 ReLU 函数作为计算最简单、又易于求导的选择,在绝大多数情况下都被用作隐含层的激活函数。输出层的激活函数与任务对输出的要求直接相关,需要根据不同的任务而具体选择。例如,二分类问题可以选用逻辑斯谛函数,多分类问题可以选用 softmax 函数,要求输出在
从上面的分析中可以看出,非线性部分对提升模型的表达能力十分重要。事实上,非线性变换相当于提升了数据的维度。例如二维平面上的点
数据维度提升的好处在于,在低维空间中线性不可分的数据,经过合适的非线性变换,在高维空间中可能变得线性可分。例如,在前文描述的异或问题中,我们通过某种非线性变换,将原本在平面上的 4 个点映射到三维空间去。如图 8-10 所示,右边的绿色平面是
8.4 反向传播
为了调整多层感知机的参数,训练神经网络,设最小化的目标函数为
比照图 8-11,
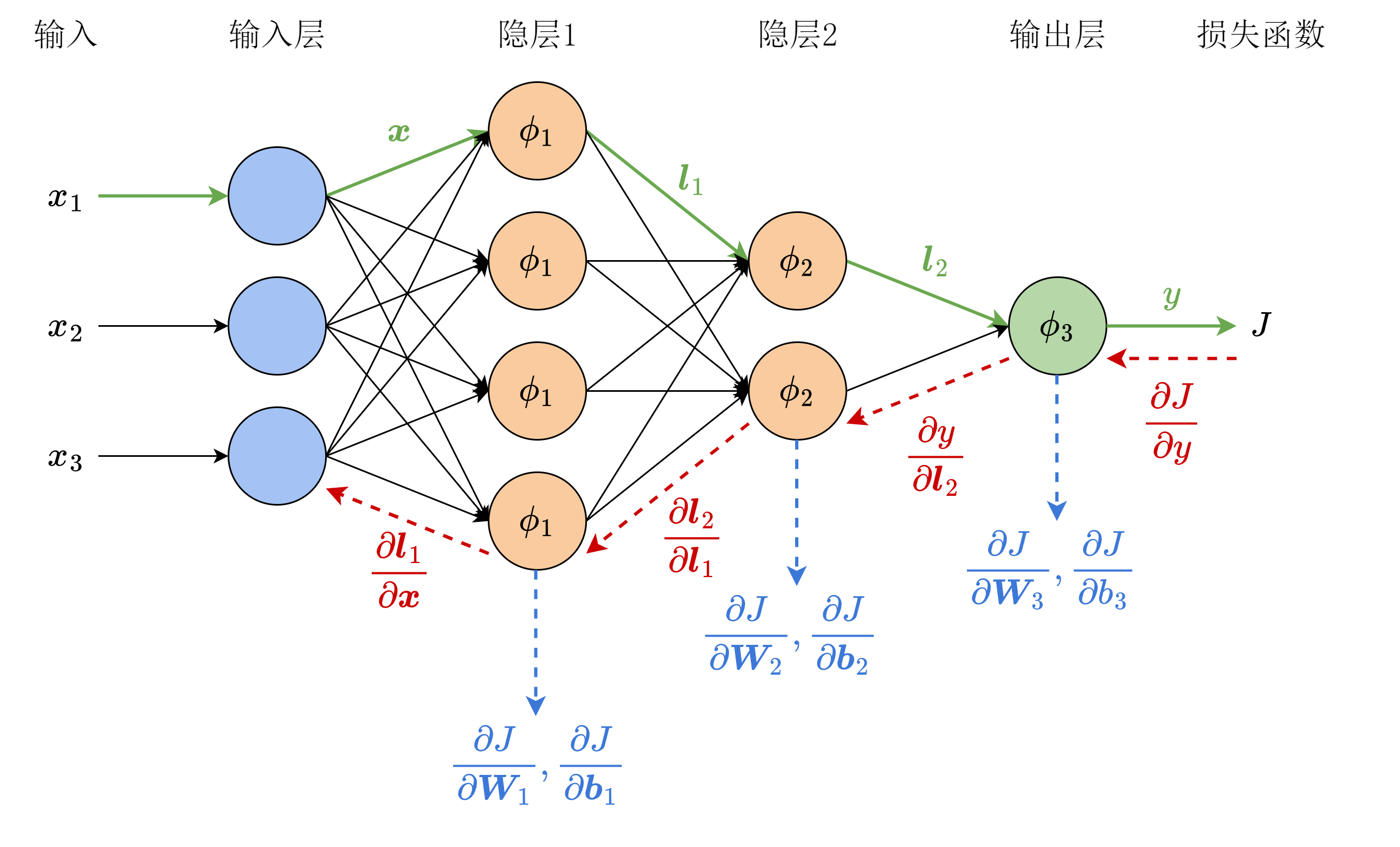
在计算过程中,我们用同样的颜色标出了重复的部分。需要注意,某些时候输入
最后,设学习率为
小故事:神经网络的雏形出现于 1943 年,它最初是由神经生理学家麦卡洛克和数学家皮兹为建立人类神经元活动的数学模型而提出的。接下来,罗森布拉特在 1958 年提出了感知机,这时的感知机只有一层,结构较为简单,本质上仍然是线性模型,无法解决包括异或问题在内的非线性问题。到了 1965 年,阿列克谢·伊瓦赫年科(Alexey Ivakhnenko)和瓦连京·拉帕(Valentin Lapa)提出了多层感知机的概念,大大提升了神经网络的表达能力。1982 年,保罗·韦伯斯(Paul Werbos)将反向传播算法应用到多层感知机上,改善了网络训练的问题。此时的 MLP 已经具有了现代神经网络的一些特点,例如反向传播、梯度下降优化等等。然而,相比于同时代的支持向量机(将在第 11 章中介绍),MLP 的数学解释模糊,很难通过数学方法保证其性能,另外神经网络模型的训练需要消耗大量计算资源。而支持向量机数学表达优美,逻辑严谨,计算简单,深受研究者的喜爱。因此,神经网络方面的研究陷入了长时间的沉寂。
2010 年左右,随着计算机硬件的进步与 GPU 算力的提升,神经网络重新出现在人们的视野中,对它的研究也慢慢增多。2012 年,用于图像分类的深度神经网络 AlexNet(将在第 9 章中介绍)在 ImageNet 比赛中以巨大优势取得了第一名,瞬间点燃了深度神经网络研究的热情。自此以后,机器学习进入了深度学习时代,深度神经网络及其各种应用成为了机器学习的绝对主流。今天,在许多领域,神经网络模型完成智能任务的水平已经超越了人类,例如 AlphaGo、AlphaFold、DALL-E、ChatGPT,越来越多的神经网络模型在不断刷新着我们对人工智能的认知。
8.5 动手实现多层感知机
接下来,我们先手动实现简单的 MLP 与反向传播算法,再讲解如何使用 PyTorch 库中的工具直接构造 MLP。首先,我们导入必要的库和数据集。本次使用的数据集 xor_dataset.csv 是异或数据集,与上文描述的离散异或问题稍有不同,该数据集包含了平面上连续的点。坐标为

import numpy as npimport matplotlib.pyplot as plt# 导入数据集data = np.loadtxt('xor_dataset.csv', delimiter=',')print('数据集大小:', len(data))print(data[:5])# 划分训练集与测试集ratio = 0.8split = int(ratio * len(data))np.random.seed(0)data = np.random.permutation(data)# y的维度调整为(len(data), 1),与后续模型匹配x_train, y_train = data[:split, :2], data[:split, -1].reshape(-1, 1)x_test, y_test = data[split:, :2], data[split:, -1].reshape(-1, 1)
数据集大小: 1000[[ 1.7641 0.4002 0. ][ 0.9787 2.2409 0. ][ 1.8676 -0.9773 1. ][ 0.9501 -0.1514 1. ][-0.1032 0.4106 1. ]]
接下来,我们开始实现 MLP 中的具体内容。由于 MLP 的前馈结构,我们可以将其拆分成许多层。每一层都应当具备 3 个基本的功能:根据输入计算输出,计算参数的梯度,更新层参数。激活函数可以抽象为单独的一层,不具有参数。为了形式统一,我们先定义基类,再让不同的层都继承基类。
# 基类class Layer:# 前向传播函数,根据输入x计算该层的输出ydef forward(self, x):raise NotImplementedError# 反向传播函数,输入上一层回传的梯度grad,输出当前层的梯度def backward(self, grad):raise NotImplementedError# 更新函数,用于更新当前层的参数def update(self, learning_rate):pass
线性层是 MLP 中最基本的结构之一,其参数为
class Linear(Layer):def __init__(self, num_in, num_out, use_bias=True):self.num_in = num_in # 输入维度self.num_out = num_out # 输出维度self.use_bias = use_bias # 是否添加偏置# 参数的初始化非常重要# 如果把参数默认设置为0,会导致Wx=0,后续计算失去意义# 我们直接用正态分布来初始化参数self.W = np.random.normal(loc=0, scale=1.0, size=(num_in, num_out))if use_bias: # 初始化偏置self.b = np.zeros((1, num_out))def forward(self, x):# 前向传播y = Wx + b# x的维度为(batch_size, num_in)self.x = xself.y = x @ self.W # y的维度为(batch_size, num_out)if self.use_bias:self.y += self.breturn self.ydef backward(self, grad):# 反向传播,按照链式法则计算# grad的维度为(batch_size, num_out)# 梯度要对batch_size取平均# grad_W的维度与W相同,为(num_in, num_out)self.grad_W = self.x.T @ grad / grad.shape[0]if self.use_bias:# grad_b的维度与b相同,为(1, num_out)self.grad_b = np.mean(grad, axis=0, keepdims=True)# 向前传播的grad维度为(batch_size, num_in)grad = grad @ self.W.Treturn graddef update(self, learning_rate):# 更新参数以完成梯度下降self.W -= learning_rate * self.grad_Wif self.use_bias:self.b -= learning_rate * self.grad_b
除了线性部分以外,MLP 中还有非线性激活函数。这里我们只实现上文讲到的逻辑斯谛函数、tanh 函数和 ReLU 函数 3 种激活函数。为了将其应用到 MLP 中,除了其表达式,我们还需要知道其梯度,以计算反向传播。它们的梯度分别为:
逻辑斯谛函数:在逻辑斯谛回归一章中已经介绍过,这里直接给出结果:
tanh 函数:
ReLU 函数:这是一个分段函数,因此其梯度也是分段的,为:
事实上,
在 处的梯度并不存在。但为了计算方便,我们人为定义其梯度与右方连续,值为 1。
除此之外,我们有时希望激活函数不改变层的输出,因此我们再额外实现恒等函数(identity function)update留空,只需要完成前向和反向传播即可。
class Identity(Layer):# 单位函数def forward(self, x):return xdef backward(self, grad):return gradclass Sigmoid(Layer):# 逻辑斯谛函数def forward(self, x):self.x = xself.y = 1 / (1 + np.exp(-x))return self.ydef backward(self, grad):return grad * self.y * (1 - self.y)class Tanh(Layer):# tanh函数def forward(self, x):self.x = xself.y = np.tanh(x)return self.ydef backward(self, grad):return grad * (1 - self.y ** 2)class ReLU(Layer):# ReLU函数def forward(self, x):self.x = xself.y = np.maximum(x, 0)return self.ydef backward(self, grad):return grad * (self.x >= 0)# 存储所有激活函数和对应名称,方便索引activation_dict = {'identity': Identity,'sigmoid': Sigmoid,'tanh': Tanh,'relu': ReLU}
最后,将全连接层和激活函数层依次拼起来,就可以得到一个简单的 MLP 了。
class MLP:def __init__(self,layer_sizes, # 包含每层大小的listuse_bias=True,activation='relu',out_activation='identity'):self.layers = []num_in = layer_sizes[0]for num_out in layer_sizes[1: -1]:# 添加全连接层self.layers.append(Linear(num_in, num_out, use_bias))# 添加激活函数self.layers.append(activation_dict[activation]())num_in = num_out# 由于输出需要满足任务的一些要求# 例如二分类任务需要输出[0,1]之间的概率值# 因此最后一层通常做特殊处理self.layers.append(Linear(num_in, layer_sizes[-1], use_bias))self.layers.append(activation_dict[out_activation]())def forward(self, x):# 前向传播,将输入依次通过每一层for layer in self.layers:x = layer.forward(x)return xdef backward(self, grad):# 反向传播,grad为损失函数对输出的梯度# 将该梯度依次回传,得到每一层参数的梯度for layer in reversed(self.layers):grad = layer.backward(grad)def update(self, learning_rate):# 更新每一层的参数for layer in self.layers:layer.update(learning_rate)
最后,我们可以直接将封装好的 MLP 当作一个黑盒子使用,并用梯度下降法进行训练。在本例中,异或数据集属于二分类任务,因此我们采用交叉熵损失,具体的训练过程如下。
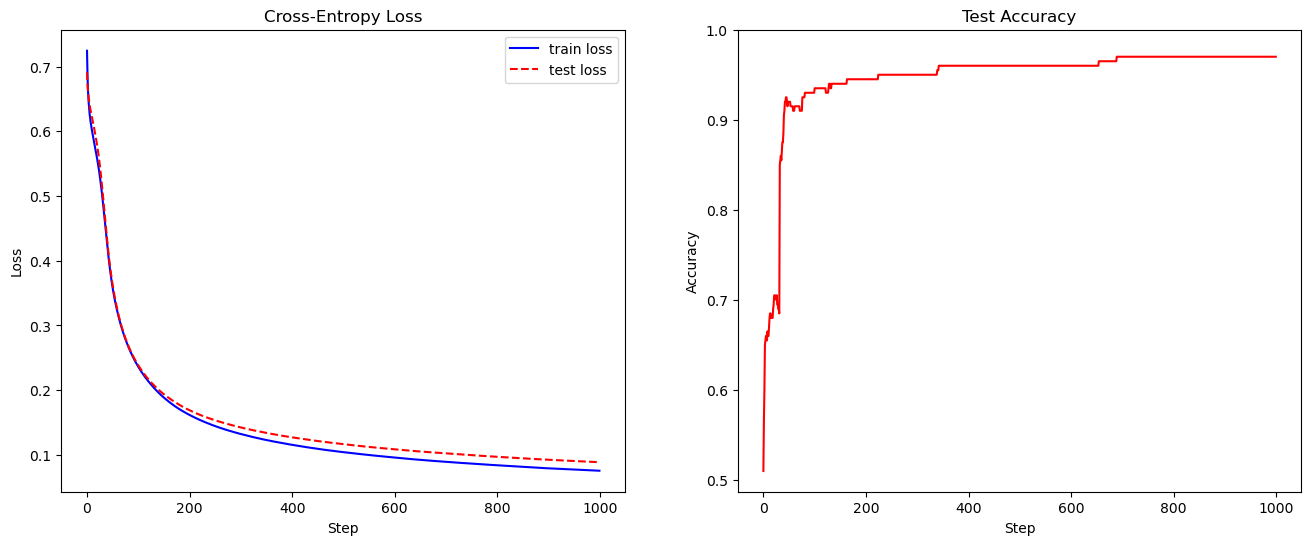
# 设置超参数num_epochs = 1000learning_rate = 0.1batch_size = 128eps=1e-7 # 用于防止除以0、log(0)等数学问题# 创建一个层大小依次为[2, 4, 1]的多层感知机# 对于二分类任务,我们用sigmoid作为输出层的激活函数,使其输出在[0,1]之间mlp = MLP(layer_sizes=[2, 4, 1], use_bias=True, out_activation='sigmoid')# 训练过程losses = []test_losses = []test_accs = []for epoch in range(num_epochs):# 我们实现的MLP支持批量输入,因此采用SGD算法st = 0loss = 0.0while True:ed = min(st + batch_size, len(x_train))if st >= ed:break# 取出batchx = x_train[st: ed]y = y_train[st: ed]# 计算MLP的预测y_pred = mlp.forward(x)# 计算梯度∂J/∂ygrad = (y_pred - y) / (y_pred * (1 - y_pred) + eps)# 反向传播mlp.backward(grad)# 更新参数mlp.update(learning_rate)# 计算交叉熵损失train_loss = np.sum(-y * np.log(y_pred + eps) \- (1 - y) * np.log(1 - y_pred + eps))loss += train_lossst += batch_sizelosses.append(loss / len(x_train))# 计算测试集上的交叉熵和精度y_pred = mlp.forward(x_test)test_loss = np.sum(-y_test * np.log(y_pred + eps) \- (1 - y_test) * np.log(1 - y_pred + eps)) / len(x_test)test_acc = np.sum(np.round(y_pred) == y_test) / len(x_test)test_losses.append(test_loss)test_accs.append(test_acc)print('测试精度:', test_accs[-1])# 将损失变化进行可视化plt.figure(figsize=(16, 6))plt.subplot(121)plt.plot(losses, color='blue', label='train loss')plt.plot(test_losses, color='red', ls='--', label='test loss')plt.xlabel('Step')plt.ylabel('Loss')plt.title('Cross-Entropy Loss')plt.legend()plt.subplot(122)plt.plot(test_accs, color='red')plt.ylim(top=1.0)plt.xlabel('Step')plt.ylabel('Accuracy')plt.title('Test Accuracy')plt.show()
测试精度: 0.97
8.6 用 PyTorch 库实现多层感知机
下面,我们用另一个常见的机器学习库 PyTorch 来实现 MLP 模型。PyTorch 是一个功能强大的机器学习框架,包含完整的机器学习训练模块和机器自动求梯度功能。因此,我们只需要实现模型从输入到输出、再计算损失函数的过程,就可以用 PyTorch 内的工具自动计算损失函数的梯度,再用梯度下降算法更新参数,省去了繁琐的手动计算过程。PyTorch 由于其功能强大、结构简单,是目前最常用的机器学习框架之一。在 PyTorch 中,MLP 需要用到的层和激活函数都已提供好,我们只需按照 8.5 节中类似的方法将其组合在一起就可以了。
import torch # PyTorch库import torch.nn as nn # PyTorch中与神经网络相关的工具from torch.nn.init import normal_ # 正态分布初始化torch_activation_dict = {'identity': lambda x: x,'sigmoid': torch.sigmoid,'tanh': torch.tanh,'relu': torch.relu}# 定义MLP类,基于PyTorch的自定义模块通常都继承nn.Module# 继承后,只需要实现forward函数,进行前向传播# 反向传播与梯度计算均由PyTorch自动完成class MLP_torch(nn.Module):def __init__(self,layer_sizes, # 包含每层大小的listuse_bias=True,activation='relu',out_activation='identity'):super().__init__() # 初始化父类self.activation = torch_activation_dict[activation]self.out_activation = torch_activation_dict[out_activation]self.layers = nn.ModuleList() # ModuleList以列表方式存储PyTorch模块num_in = layer_sizes[0]for num_out in layer_sizes[1:]:# 创建全连接层self.layers.append(nn.Linear(num_in, num_out, bias=use_bias))# 正态分布初始化,采用与前面手动实现时相同的方式normal_(self.layers[-1].weight, std=1.0)# 偏置项为全0self.layers[-1].bias.data.fill_(0.0)num_in = num_outdef forward(self, x):# 前向传播# PyTorch可以自行处理batch_size等维度问题# 我们只需要让输入依次通过每一层即可for i in range(len(self.layers) - 1):x = self.layers[i](x)x = self.activation(x)# 输出层x = self.layers[-1](x)x = self.out_activation(x)return x
最后,定义超参数,用相同的方式训练 PyTorch 模型,最终得到的结果与手动实现的相近。
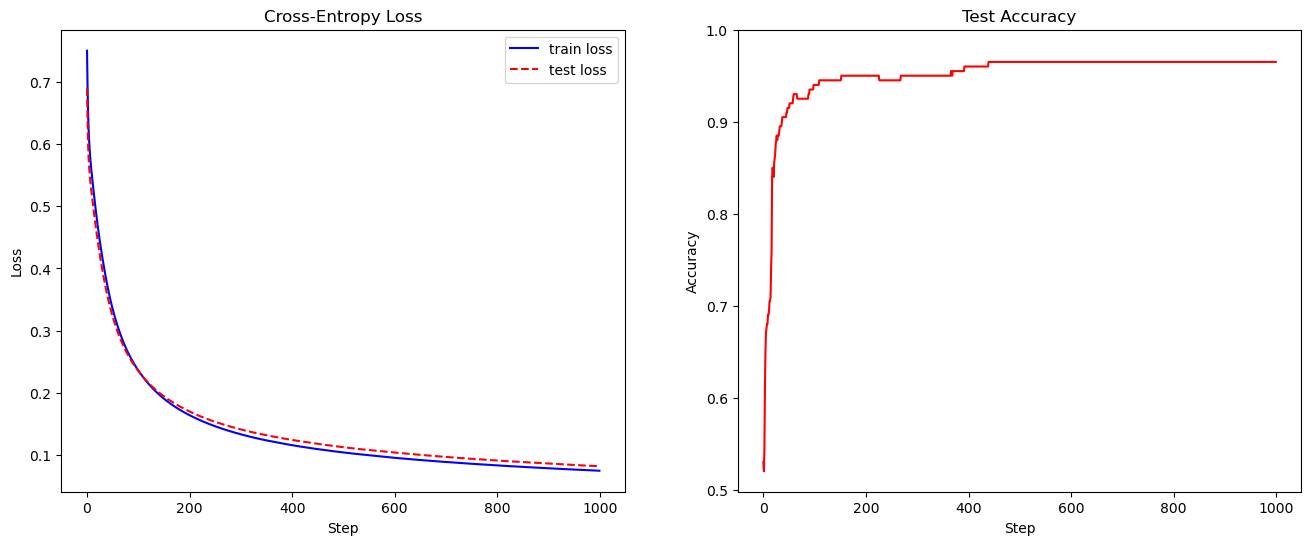
# 设置超参数num_epochs = 1000learning_rate = 0.1batch_size = 128eps = 1e-7torch.manual_seed(0)# 初始化MLP模型mlp = MLP_torch(layer_sizes=[2, 4, 1], use_bias=True,out_activation='sigmoid')# 定义SGD优化器opt = torch.optim.SGD(mlp.parameters(), lr=learning_rate)# 训练过程losses = []test_losses = []test_accs = []for epoch in range(num_epochs):st = 0loss = []while True:ed = min(st + batch_size, len(x_train))if st >= ed:break# 取出batch,转为张量x = torch.tensor(x_train[st: ed],dtype=torch.float32)y = torch.tensor(y_train[st: ed],dtype=torch.float32).reshape(-1, 1)# 计算MLP的预测# 调用模型时,PyTorch会自动调用模型的forward方法# y_pred的维度为(batch_size, layer_sizes[-1])y_pred = mlp(x)# 计算交叉熵损失train_loss = torch.mean(-y * torch.log(y_pred + eps) \- (1 - y) * torch.log(1 - y_pred + eps))# 清空梯度opt.zero_grad()# 反向传播train_loss.backward()# 更新参数opt.step()# 记录累加损失,需要先将损失从张量转为numpy格式loss.append(train_loss.detach().numpy())st += batch_sizelosses.append(np.mean(loss))# 计算测试集上的交叉熵# 在不需要梯度的部分,可以用torch.inference_mode()加速计算with torch.inference_mode():x = torch.tensor(x_test, dtype=torch.float32)y = torch.tensor(y_test, dtype=torch.float32).reshape(-1, 1)y_pred = mlp(x)test_loss = torch.sum(-y * torch.log(y_pred + eps) \- (1 - y) * torch.log(1 - y_pred + eps)) / len(x_test)test_acc = torch.sum(torch.round(y_pred) == y) / len(x_test)test_losses.append(test_loss.detach().numpy())test_accs.append(test_acc.detach().numpy())print('测试精度:', test_accs[-1])# 将损失变化进行可视化plt.figure(figsize=(16, 6))plt.subplot(121)plt.plot(losses, color='blue', label='train loss')plt.plot(test_losses, color='red', ls='--', label='test loss')plt.xlabel('Step')plt.ylabel('Loss')plt.title('Cross-Entropy Loss')plt.legend()plt.subplot(122)plt.plot(test_accs, color='red')plt.ylim(top=1.0)plt.xlabel('Step')plt.ylabel('Accuracy')plt.title('Test Accuracy')plt.show()
测试精度: 0.965
8.7 本章小结
人工神经网络是深度学习的基础,而现代人工智能的大部分应用都涉及深度学习。可以说,现在一切实用的人工智能模型都包含了不同结构的神经网络。本章讲解了神经网络的发展历程,以及一个曾经得到大规模应用的重要神经网络模型——多层感知机。其中包含的前馈结构、反向传播等思想,深刻地影响了后续神经网络的发展。在接下来的章节中,我们还会遇到更复杂的神经网络模型,但其基本思想都是一致的。希望读者能仔细理解本章讲述的内容,完成章后习题,并动手实现、调整超参数,观察训练结果的变化,对神经网络的特点有更深入的理解。关于深度学习的系统性讲解和练习,推荐读者们参阅《动手学深度学习》
习题
1960 年代,马文·明斯基(Marvin Minsky)和西摩·佩珀特(Seymour Papert)利用____证明了感知机的局限性,导致神经网络的研究陷入寒冬。 A. 梯度消失问题 B. 异或问题 C. 线性分类问题
下列关于神经网络的说法正确的是: A. 神经网络的设计仿照生物的神经元,已经可以完成和生物神经一样的功能。 B. 神经元只能通过前馈方式连接,否则无法进行反向传播。 C. 多层感知机相比于单层感知机有很大提升,其核心在于非线性激活函数。 D. 多层感知机没有考虑不同特征之间的关联,因此建模能力不如双线性模型。
为什么(结构固定的)神经网络是参数化模型?它对输入的参数化假设是什么?
试计算逻辑斯谛函数、tanh 梯度的取值区间,并根据反向传播的公式思考:当 MLP 的层数比较大时,其梯度计算会有什么影响?
8.3 节中提到,将值域为
的 变形可以使值域拓展到 。对于更一般的情况,推导将 区间均匀映射到 区间的变换 。均匀映射可以理解为,对于任意 ,都有 。 神经网络训练同样可能产生过拟合现象。尝试修改代码中的损失函数,为多层感知机加入
正则化约束,其具体形式为所有权重和偏置项的平方和 。在 Pytorch 中, 正则化约束通常通过调整优化器的参数 weight_decay来实现,调整该参数的值并观察效果。
参考文献
[1] 普适逼近定理的论文:Cybenko G. Approximation by superpositions of a sigmoidal function[J]. Mathematics of control, signals and systems, 1989, 2(4): 303-314.
[2] 阿斯顿·张,李沐,扎卡里·C. 立顿,亚历山大·J·斯莫拉. 《动手学深度学习》. 人民邮电出版社. ISBN:9787115490841. 2019.