第 15 章 主成分分析
在上一章k均值聚类中,我们介绍了无监督学习的重要问题之一:聚类问题。结尾处我们提到,在解决复杂聚类问题时,第一步通常不会直接使用k均值算法,而是会先用其他手段提取数据的有用特征。对于高维复杂数据来说,其不同维度代表的特征可能存在关联,还有可能存在无意义的噪声干扰。因此,无论后续任务是有监督学习还是无监督学习,我们都希望能先从中提取出具有代表性、能最大限度保留数据本身信息的几个特征,从而降低数据维度,简化之后的分析和计算。这一过程通常称为数据降维(dimensionality reduction),同样是无监督学习中的重要问题。本章就来介绍数据降维中最经典的算法主成分分析(principal component analysis,PCA)。
15.1 主成分与方差
顾名思义,PCA的含义是将高维数据中的主要成分找出来。设原始数据
PCA算法不仅希望变换后的数据特征线性无关,更要求这些特征之间相互独立,也即任意两个不同特征之间的协方差为零。因此,PCA算法在计算数据的主成分时,会从第一个主成分开始依次计算,并保证每个主成分与之前的所有主成分都是正交的,直到选取了预先设定的
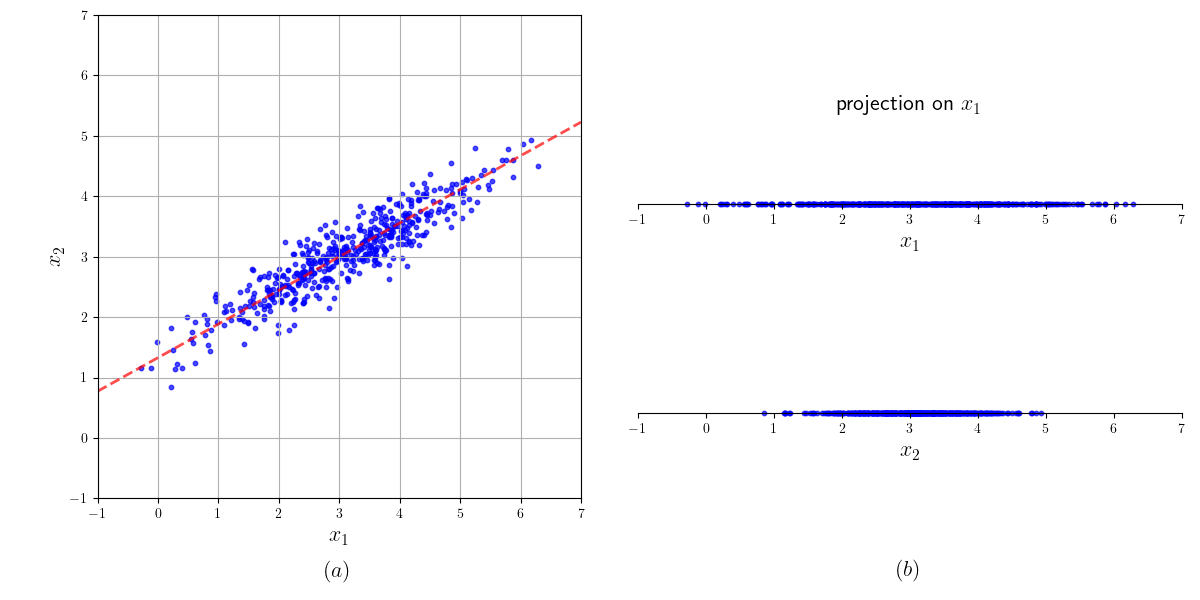
图15-1(b)展示了数据分别向
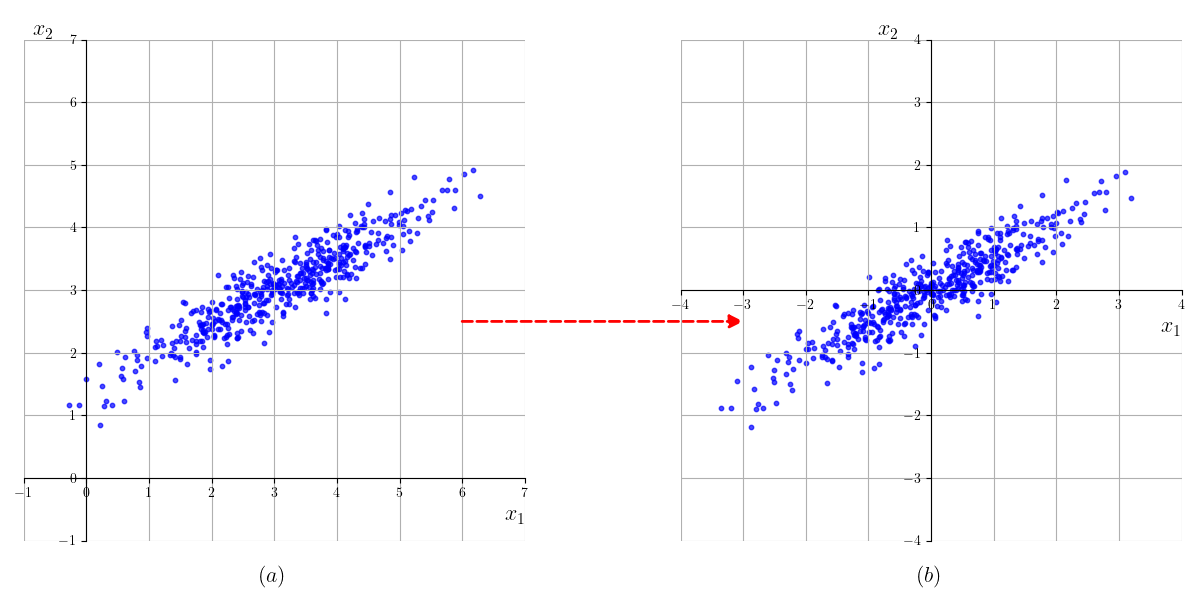
为了方便计算,我们通常要先对数据进行中心化,把当前每个特征都变为均值为0的分布。用
将数据中心化,得到:
以上面的高斯分布为例,变换后的图像如图15-2所示,其中心点已经从
15.2 用特征分解计算PCA
为了找到方差最大的方向,我们先来计算样本在某个方向上的投影。设
矩阵
在求解该问题之前,我们先来介绍矩阵的特征值(eigenvalue)与特征分解(eigendecomposition)相关的知识。对于方阵
从而也还是特征向量。简单来说,矩阵
的特征值及其对应的单位特征向量有两组,分别为
我们可以从线性变换的角度来理解矩阵的特征值和特征向量。一个
从这一角度继续,我们可以引入正定(positive definite)矩阵和半正定(positive semidefinite)矩阵的概念。如果对任意非零向量
为什么我们要引入半正定矩阵呢?在上面的优化问题中,我们得到的目标函数是
根据定义,
有兴趣的读者可以在线性代数的相关资料中找到该性质的证明。利用该性质,记
于是,
设特征向量
其中,
利用特征分解,我们可以很容易地计算
这里,我们用到了
在上面的优化问题中,我们还要求
因此,原优化问题等价于:
由于
上面的计算结果表面,用PCA寻找第一个主成分的过程就是求解PCA最大特征值及其对应特征向量的过程。事实上,由于协方差矩阵
15.3 动手实现PCA算法
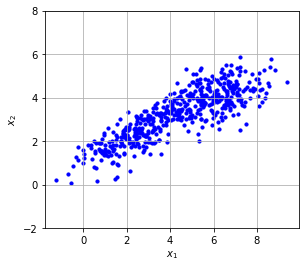
下面,我们在NumPy库中线性代数工具的帮助下实现PCA算法。首先,我们导入数据集PCA_dataset.csv并将其可视化。数据集的每一行包含两个数
import numpy as npimport matplotlib.pyplot as plt# 导入数据集data = np.loadtxt('PCA_dataset.csv', delimiter=',')print('数据集大小:', len(data))# 可视化plt.figure()plt.scatter(data[:, 0], data[:, 1], color='blue', s=10)plt.axis('square')plt.ylim(-2, 8)plt.grid()plt.xlabel(r'$x_1$')plt.ylabel(r'$x_2$')plt.show()
数据集大小: 500
接下来,我们按上面讲解的方式实现PCA算法。numpy.linalg中提供了许多线性代数相关的工具,可以帮助我们计算矩阵的特征值与特征向量。
def pca(X, k):d, m = X.shapeif d < k:print('k应该小于特征数')return X, None# 中心化X = X - np.mean(X, axis=0)# 计算协方差矩阵cov = X.T @ X# 计算特征值和特征向量eig_values, eig_vectors = np.linalg.eig(cov)# 获取最大的k个特征值的下标idx = np.argsort(-eig_values)[:k]# 对应的特征向量W = eig_vectors[:, idx]# 降维X = X @ Wreturn X, W
最后,我们在数据集上测试该PCA函数的效果,并将变换后的数据绘制出来。由于原始数据只有二维,为了演示PCA的效果,我们仍然设置
X, W = pca(data, 2)print('变换矩阵:\n', W)# 绘图plt.figure()plt.scatter(X[:, 0], X[:, 1], color='blue', s=10)plt.axis('square')plt.ylim(-5, 5)plt.grid()plt.xlabel(r'$x_1$')plt.ylabel(r'$x_2$')plt.show()
变换矩阵:[[ 0.90322448 -0.42916843][ 0.42916843 0.90322448]]

15.4 用sklearn实现PCA算法
Sklearn库中同样提供了实现好的PCA算法,我们可以直接调用它来完成PCA变换。可以看出,虽然结果图像与我们上面直接实现的版本有180
from sklearn.decomposition import PCA# 中心化X = data - np.mean(data, axis=0)pca_res = PCA(n_components=2).fit(X)W = pca_res.components_.Tprint ('sklearn计算的变换矩阵:\n', W)X_pca = X @ W# 绘图plt.figure()plt.scatter(X_pca[:, 0], X_pca[:, 1], color='blue', s=10)plt.axis('square')plt.ylim(-5, 5)plt.grid()plt.xlabel(r'$x_1$')plt.ylabel(r'$x_2$')plt.show()
sklearn计算的变换矩阵:[[-0.90322448 0.42916843][-0.42916843 -0.90322448]]

15.5 本章小结
本章介绍了数据降维的常用算法之一:PCA算法。数据降维是无监督学习的重要问题,在机器学习中有广泛的应用。由于从现实生活中采集的数据往往非常复杂,包含大量的冗余信息,通常我们必须对其进行降维,选出有用的特征供给后续模型使用。此外,有时我们还希望将高维数据可视化,也需要从数据中挑选2到3个最有价值的维度,将数据投影后绘制出来。除了PCA之外,现在常用的降维算法还有线性判别分析(linear discriminant analysis,LDA)、一致流形逼近与投影(uniform manifold approximation and projection,UMAP)、t分布随机近邻嵌入(t-distributed stochastic neighbor embedding,t-SNE)等。这些算法的特点各不相同,也有不同的适用场景。
关于PCA的计算方式,由于计算协方差矩阵
最后,读者可以在SETOSA网站的PCA算法动态展示平台上观察PCA的结果随数据分布的变化,加深对算法的理解。
习题
PCA算法成立的的条件与数据分布的形式是否有关系?尝试计算下列特殊数据分布的第一个主成分,和你的直观感受一样吗?
- 直线
上的点 ; - 两边不等长的十字形
; - 三维中单位立方体的
个顶点 。
- 直线
当有数据集中包含多个不同类别的数据时,PCA还可以用来把数据区分开,完成类似于聚类的效果。这样做的原理是什么?(提示:考虑主成分与方差的关系。)
利用sklearn库中的
sklearn.datasets.load_iris()函数加载鸢尾花数据集。该数据集中共包含3种不同的鸢尾花,每一行代表一朵鸢尾花,并给出了花萼长度、花瓣长度等特征,以及鸢尾花所属的种类。用PCA把其中的特征数据降到两维,画出降维后数据的分布,并为每种鸢尾花涂上不同颜色。不同种的样本是否被分开了?