- 4.1 线性回归的映射形式和学习目标
- 4.2 线性回归的解析方法
- 4.3 动手实现线性回归的解析方法
- 4.4 使用 sklearn 中的线性模型
- 4.5 梯度下降算法
- 4.6 学习率对迭代的影响
- 4.7 本章小结
- 习题
第 4 章 线性回归
第 3 章中介绍的 KNN 算法是最简单的机器学习算法之一,本章将逐步引入一些数学工具,讲解另一个较为简单的机器学习算法——线性回归(linear regression)。与上一章介绍的 k 近邻算法不同,线性回归是一种基于数学模型的算法,其首先假设数据集中的样本与标签之间存在线性关系,再建立线性模型求解该关系中的各个参数。在实际生活中,线性回归算法因为其简单易算,在统计学、经济学、天文学、物理学等领域中都有着广泛应用。下面,我们从线性回归的数学描述开始,讲解线性回归的原理和实践。
4.1 线性回归的映射形式和学习目标
顾名思义,在“线性”回归问题中,我们假设输入与输出成线性关系。设输入
其中
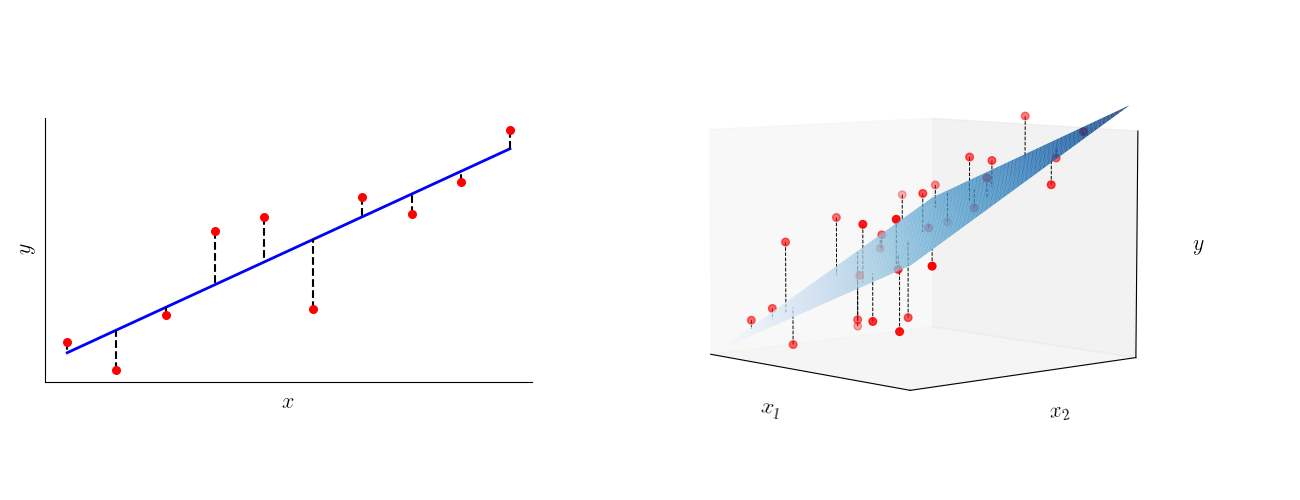
在机器学习中,我们一般先设计损失函数,由模型预测的标签与真实标签之间的误差计算损失的值,并通过最小化损失函数来训练模型,调整模型参数。设共有
其中
式中的系数
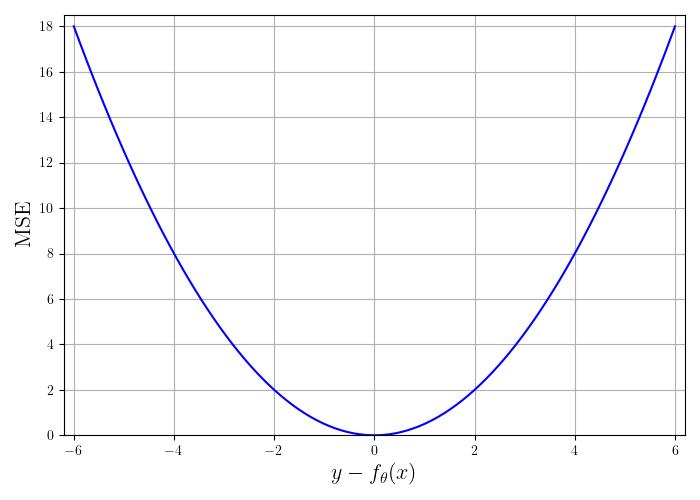
将该损失函数代入总误差可得
这一总损失函数称为均方误差(mean squared error,MSE),是最常用的损失函数之一。因此,线性回归问题的优化目标为:
4.2 线性回归的解析方法
为了使表达式更简洁,我们进一步将数据聚合,把输入向量和标签组合成矩阵:
其中
这里的损失函数事实上是所有样本平方误差的和,与 MSE 相差一步取平均值,即除以样本总数
为了求函数
计算偏导数,得到:
通过上式得到
于是,算法学到的模型对训练数据的预测为:
下面,我们用 NumPy 库中的线性代数相关工具,直接用解析解来计算线性回归模型。
4.3 动手实现线性回归的解析方法
本章采用的数据集由房屋信息与房屋售价组成。其中,房屋信息包含所在区域平均收入、区域平均房屋年龄、区域平均房间数、区域平均卧室数、人口等。我们希望根据某一区域中房屋的整体信息,用线性模型预测该区域中房屋的平均售价。表 4-1 展示了其中的 3 条数据。
表 4-1 房屋信息数据示例
| 区域平均收入 | 区域平均房屋年龄 | 区域平均房间数 | 区域平均卧室数 | 区域人口 | 房屋售价 |
|---|---|---|---|---|---|
| 79545.46 | 5.68 | 7.01 | 4.09 | 23086.80 | 1059033.56 |
| 79248.64 | 6.00 | 6.73 | 3.09 | 40173.07 | 1505890.91 |
| 61287.06 | 5.86 | 8.51 | 5.13 | 36882.15 | 1058987.98 |
我们首先读入并处理数据,并且划分训练集与测试集,为后续算法实现做准备。这里我们会用到 sklearn 中的数据处理工具包preprocessing中的StandardScalar类。该类的fit函数可以根据输入的数据计算平均值和方差,并用计算结果将数据标准化,使其均值为 0、方差为 1。例如,数组[0, 1, 2, 3, 4]经过标准化,就变为[-1.41, -0.71, 0.00, 0.71, 1.41]。对输入数据进行标准化,可以避免不同特征的数据之间数量级差距过大导致的问题。以上面列出的数据条目为例,区域平均收入在
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.ticker import MaxNLocatorfrom sklearn.preprocessing import StandardScaler# 从源文件加载数据,并输出查看数据的各项特征lines = np.loadtxt('USA_Housing.csv', delimiter=',', dtype='str')header = lines[0]lines = lines[1:].astype(float)print('数据特征:', ', '.join(header[:-1]))print('数据标签:', header[-1])print('数据总条数:', len(lines))# 划分训练集与测试集ratio = 0.8split = int(len(lines) * ratio)np.random.seed(0)lines = np.random.permutation(lines)train, test = lines[:split], lines[split:]# 数据归一化scaler = StandardScaler()scaler.fit(train) # 只使用训练集的数据计算均值和方差train = scaler.transform(train)test = scaler.transform(test)# 划分输入和标签x_train, y_train = train[:, :-1], train[:, -1].flatten()x_test, y_test = test[:, :-1], test[:, -1].flatten()
数据特征: Avg. Area Income, Avg. Area House Age, Avg. Area Number of Rooms, Avg. Area Number of Bedrooms, Area Population数据标签: Price数据总条数: 5000
我们按照 4.2 的推导,利用 NumPy 库中的工具直接进行矩阵运算,并输出预测值与真实值的误差。衡量误差的标准也有很多,这里我们采用均方根误差(rooted mean squared error,RMSE)。对于真实值
RMSE 与 MSE 非常接近,但是平方再开方的操作使得 RMSE 应当与
# 在X矩阵最后添加一列1,代表常数项X = np.concatenate([x_train, np.ones((len(x_train), 1))], axis=-1)# @ 表示矩阵相乘,X.T表示矩阵X的转置,np.linalg.inv函数可以计算矩阵的逆theta = np.linalg.inv(X.T @ X) @ X.T @ y_trainprint('回归系数:', theta)# 在测试集上使用回归系数进行预测X_test = np.concatenate([x_test, np.ones((len(x_test), 1))], axis=-1)y_pred = X_test @ theta# 计算预测值和真实值之间的RMSErmse_loss = np.sqrt(np.square(y_test - y_pred).mean())print('RMSE:', rmse_loss)
回归系数: [ 6.50881254e-01 4.67222833e-01 3.38466198e-01 6.17275856e-034.26857089e-01 -1.46033359e-14]RMSE: 0.28791834247503534
4.4 使用 sklearn 中的线性模型
接下来,我们使用 sklearn 中已有的工具LinearRegression来实现线性回归模型。可以看出,该工具计算得到的回归系数与 RMSE 都和我们用解析方式计算的结果相同。
from sklearn.linear_model import LinearRegression# 初始化线性模型linreg = LinearRegression()# LinearRegression的方法中已经考虑了线性回归的常数项,所以无须再拼接1linreg.fit(x_train, y_train)# coef_是训练得到的回归系数,intercept_是常数项print('回归系数:', linreg.coef_, linreg.intercept_)y_pred = linreg.predict(x_test)# 计算预测值和真实值之间的RMSErmse_loss = np.sqrt(np.square(y_test - y_pred).mean())print('RMSE:', rmse_loss)
回归系数: [0.65088125 0.46722283 0.3384662 0.00617276 0.42685709] -1.4635041882766192e-14RMSE: 0.2879183424750354
4.5 梯度下降算法
虽然对于线性回归问题,我们在选取平方损失函数后可以通过数学推导得到问题的解析解。但是,这样的做法有一些严重的缺陷。第一,解析解中涉及大量的矩阵运算,非常耗费时间和空间。假设样本数目为
回顾梯度的意义,我们可以发现,梯度的方向就是函数值上升最快的方向。那么反过来说,梯度的反方向就是函数值下降最快的方向。如果我们将参数不断沿梯度的反方向调整,就可以使函数值以最快的速度减小。当函数值几乎不再改变时,我们就找到了函数的一个局部极小值。而对于部分较为特殊的函数,其局部极小值就是其全局最小值。在此情况下,梯度下降算法最后可以得到全局最优解。我们暂时不考虑具体哪些函数满足这样的条件,而是按照直观的思路进行简单的推导。设模型参数为
其中,
如果写成矩阵形式,上式就等价于:
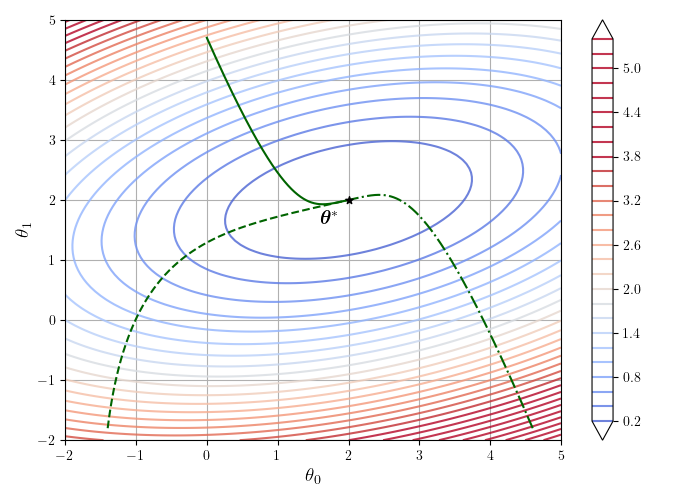
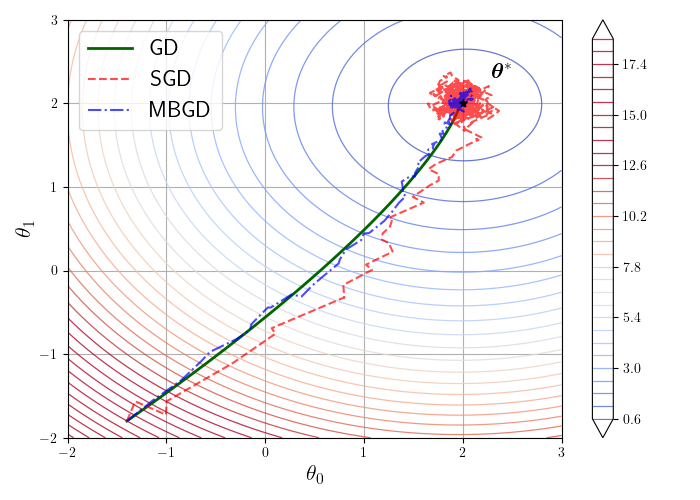
图 4-3 展示了在二维情况下 MSE 损失函数梯度下降的迭代过程。图中的椭圆线条是损失函数的等值线,颜色表示损失函数值的大小,越偏蓝色的地方损失越小,越偏红色的地方损失越大。3 条曲线代表了从 3 个不同的初值进行梯度下降的过程中参数值的变化情况。可以看出,在 MSE 损失的情况下,无论初始值如何,参数都不断沿箭头所指的梯度反方向变化,最终到达损失函数的最小值点
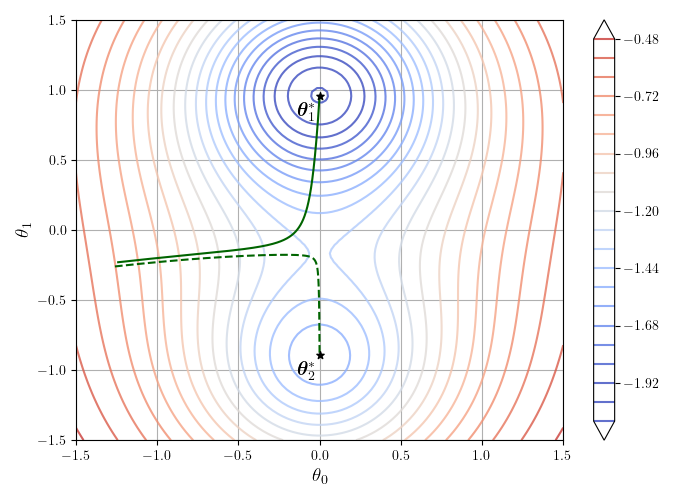
如果需要优化的损失函数是非凸的,梯度下降就可能陷入局部极小值,无法达到全局最优。如图 4-4 所示,损失函数在空间上有两个局部极小值点
梯度下降的公式已经不含有矩阵求逆和矩阵相乘等时间复杂度很高的运算,但当样本量很大时,计算矩阵与向量相乘仍然很耗时,矩阵的存储问题也没有解决。因此,我们可以每次只随机选一个样本计算其梯度,并进行梯度下降。设选取的样本为
由于每次只计算一个样本,梯度下降的时间复杂度大大降低了,这样的算法就称为随机梯度下降法(stochastic gradient decent,SGD)。然而,随机梯度下降的不稳定性很高。由于单个样本计算出的梯度方向可能与所有样本算出的真正梯度方向不同,如果我们要优化的函数不是凸函数,SGD 算法就可能从原定路线偏离,收敛到其他极小值点去。因此,为了在稳定性与时间复杂度之间取得平衡,我们一般使用小批量梯度下降(mini-batch gradient decent,MBGD)算法,将样本随机分成许多大小较小的批量(batch)。每次迭代时,选取一个批量来计算函数梯度,以此估计用完整样本计算的结果。假如批量大小为
可以看出,MBGD 算法当
虽然 SGD 与 MBGD 理论上是不同的算法,但是作为 SGD 的扩展,在现代深度学习中 SGD 已经成为了 MBGD 的代名词,在不少代码库中 SGD 就是 MBGD。因此,本书中不再区分这两个算法,统一称为 SGD。下面,我们来动手实现 SGD 算法完成相同的线性回归任务,并观察 SGD 算法的表现。首先,我们实现随机划分数据集和产生批量的函数。
# 该函数每次返回大小为batch_size的批量# x和y分别为输入和标签# 若shuffle = True,则每次遍历时会将数据重新随机划分def batch_generator(x, y, batch_size, shuffle=True):# 批量计数器batch_count = 0if shuffle:# 随机生成0到len(x)-1的下标idx = np.random.permutation(len(x))x = x[idx]y = y[idx]while True:start = batch_count * batch_sizeend = min(start + batch_size, len(x))if start >= end:# 已经遍历一遍,结束生成breakbatch_count += 1yield x[start: end], y[start: end]
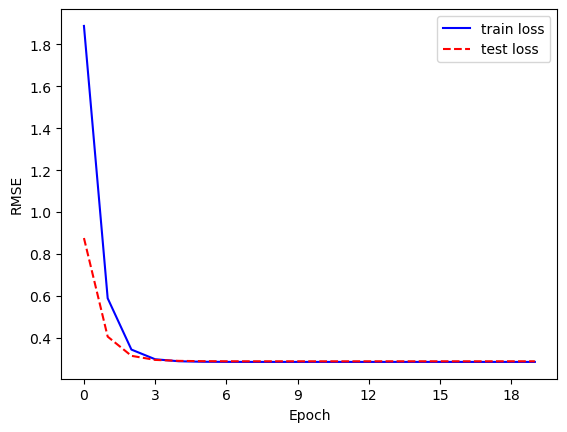
接下来是算法的主体部分。我们提前设置好迭代次数、学习率和批量大小,并用上面的公式不断迭代,最后将迭代过程中 RMSE 的变化曲线绘制出来。可以看出,最终得到的结果和上面精确计算的结果虽然有差别,但已经十分接近,RMSE 也在可以接受的范围内。另外,在模型优化中,我们一般将一次参数更新称为一步(step),例如进行一次梯度下降;而将遍历一次所有训练数据称为一轮(epoch)。
def SGD(num_epoch, learning_rate, batch_size):# 拼接原始矩阵X = np.concatenate([x_train, np.ones((len(x_train), 1))], axis=-1)X_test = np.concatenate([x_test, np.ones((len(x_test), 1))], axis=-1)# 随机初始化参数theta = np.random.normal(size=X.shape[1])# 随机梯度下降# 为了观察迭代过程,我们记录每一次迭代后在训练集和测试集上的均方根误差train_losses = []test_losses = []for i in range(num_epoch):# 初始化批量生成器batch_g = batch_generator(X, y_train, batch_size, shuffle=True)train_loss = 0for x_batch, y_batch in batch_g:# 计算梯度grad = x_batch.T @ (x_batch @ theta - y_batch)# 更新参数theta = theta - learning_rate * grad / len(x_batch)# 累加平方误差train_loss += np.square(x_batch @ theta - y_batch).sum()# 计算训练和测试误差train_loss = np.sqrt(train_loss / len(X))train_losses.append(train_loss)test_loss = np.sqrt(np.square(X_test @ theta - y_test).mean())test_losses.append(test_loss)# 输出结果,绘制训练曲线print('回归系数:', theta)return theta, train_losses, test_losses# 设置迭代次数,学习率与批量大小num_epoch = 20learning_rate = 0.01batch_size = 32# 设置随机种子np.random.seed(0)_, train_losses, test_losses = SGD(num_epoch, learning_rate, batch_size)# 将损失函数关于运行次数的关系制图,可以看到损失函数先一直保持下降,之后趋于平稳plt.plot(np.arange(num_epoch), train_losses, color='blue',label='train loss')plt.plot(np.arange(num_epoch), test_losses, color='red',ls='--', label='test loss')# 由于epoch是整数,这里把图中的横坐标也设置为整数# 该步骤也可以省略plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))plt.xlabel('Epoch')plt.ylabel('RMSE')plt.legend()plt.show()
回归系数: [ 0.65357756 0.46682964 0.33885411 0.00720843 0.42751035 -0.00273407]
4.6 学习率对迭代的影响
在梯度下降算法中,学习率是一个非常关键的参数。我们调整上面设置的学习率,观察训练结果的变化。
_, loss1, _ = SGD(num_epoch=num_epoch, learning_rate=0.1,batch_size=batch_size)_, loss2, _ = SGD(num_epoch=num_epoch, learning_rate=0.001,batch_size=batch_size)plt.plot(np.arange(num_epoch), loss1, color='blue',label='lr=0.1')plt.plot(np.arange(num_epoch), train_losses, color='red',ls='--', label='lr=0.01')plt.plot(np.arange(num_epoch), loss2, color='green',ls='-.', label='lr=0.001')plt.xlabel('Epoch')plt.ylabel('RMSE')plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))plt.legend()plt.show()
回归系数: [0.64542258 0.47047873 0.33188398 0.00325404 0.42479699 0.00237965]回归系数: [0.59247915 0.58561574 0.26554358 0.10173112 0.49435997 0.13108641]
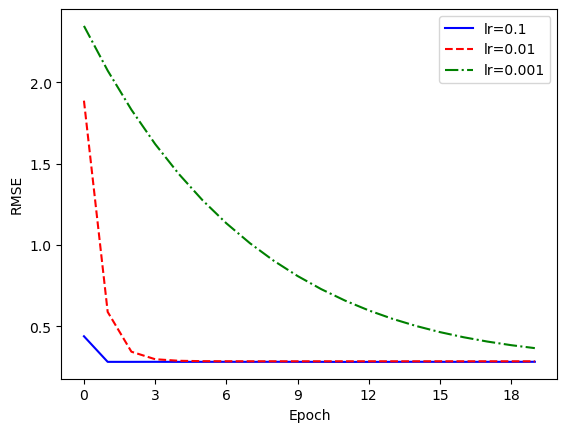
可以看出,随着学习率增大,算法的收敛速度明显加快。那么,学习率是不是越大越好呢?我们将学习率继续上调到 1.5 观察结果。
_, loss3, _ = SGD(num_epoch=num_epoch, learning_rate=1.5, batch_size=batch_size)print('最终损失:', loss3[-1])plt.plot(np.arange(num_epoch), np.log(loss3), color='blue', label='lr=1.5')plt.xlabel('Epoch')plt.ylabel('log RMSE')plt.gca().xaxis.set_major_locator(MaxNLocator(integer=True))plt.legend()plt.show()
回归系数: [-2.56988308e+83 -1.41878767e+82 -5.79381773e+83 -6.05363125e+83-1.04933464e+83 -2.27170862e+83]最终损失: 3.98388523469088e+83
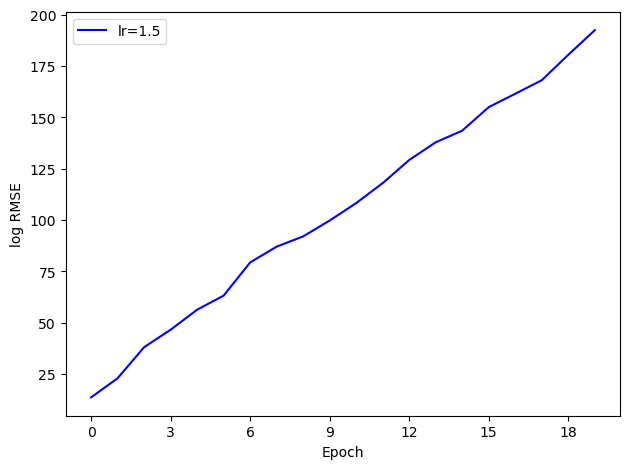
然而,算法的 RMSE 随着迭代不但没有减小,反而发散了。注意,由于原始的损失数值过大,我们将纵轴改为了损失的对数,因此图中的直线对应于实际的指数增长。上图最后的损失约为
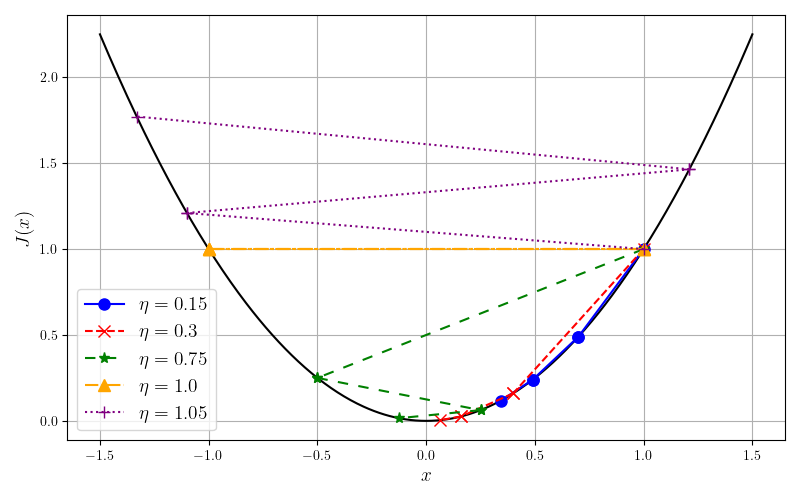
显然,该函数在
- 当
时, ,有 。 在迭代过程中始终与 符号相同,且迭代过程可以收敛。 - 当
时, ,同样有 。但 每次迭代都会改变符号,迭代过程可以收敛。 - 当
时, ,迭代过程变为 。因此 始终在 间变化,迭代不收敛。 - 当
时, ,有 ,每次迭代 的符号会改变,且向无穷大发散。
图 4-6 展示了在初始点
4.7 本章小结
在本章中,我们学习了线性回归问题和求解方法。线性回归是机器学习中最基础的参数化学习模型,线性回归任务是机器学习中最基础的有监督学习任务。本周讨论了求解线性回归问题的不同方法,并在房屋售价数据集上进行了实践。解析方法与梯度下降方法各有优劣。前者能直接得到精确的解,但计算的时空开销较大,其表达式一般情况下也难以计算;后者通过数值近似方法,用较小的时空复杂度得到了与精确解接近的结果,但是往往需要手动调整学习率和迭代次数。整体而言,梯度下降方法更为常用,它也衍生出了许多更有效、更快速的优化方法,是现代深度学习的基础之一。
习题
以下关于线性回归的表述错误的是: A. 线性回归中的“线性”,是指模型参数
之间不存在非线性耦合项。 B. 线性回归常用均方误差作为损失函数。 C. 可以是一个线性回归得到的模型表达式。 D. 损失函数用于度量预测值和真实值之间的误差。 以下关于梯度下降的表述错误的是: A. 使用梯度信息来最小化目标函数时,参数的更新方向是其梯度的负方向。 B. 梯度下降中设置更大的学习率就可以更快地收敛到全局最优。 C. 随机梯度下降是一种权衡训练速度和稳定性的方法。 D. 损失函数的优化目标是最小化模型在训练集上的误差。
假设在线性回归问题中,数据集有两个样本
和 ,尝试用解析方式计算线性回归的参数 。计算中是否遇到了问题? 针对 1 维线性回归问题,基于训练数据
(其中第 1 维为唯一特征 ,第 2 维为标签 ),构建线性回归模型 ,并完成以下任务: - 试作图展示均方误差和参数
, 的函数关系; - 并以不同的参数初始化位置和学习率,画出不同的参数学习轨迹;
- 尝试增大学习率,观察参数学习出现的发散现象。
- 试作图展示均方误差和参数
调整 SGD 算法中
batch_size的大小,观察结果的变化。对较大规模的数据集,batch_size过小和过大分别有什么缺点?4.3 节 SGD 算法的代码中,我们采用了固定迭代次数的方式,但是这样无法保证程序执行完毕时迭代已经收敛,也有可能迭代早已收敛而程序还在运行。另一种方案是,如果损失函数值连续
次迭代都没有减小,或者减小的量小于某个预设精度 (例如 ),就终止迭代。请实现该控制方案,并思考它和固定迭代次数之间的利弊。能不能将这两种方案同时使用呢?